
Recommendations, Analyses, and Data for Health Services Research, Diagnosis, and Prognosis Clinic
Archive
Current Notes- 23Dec13
- 9Dec13
- 11Nov13
- 28Oct13
- 21Oct13
- 14Oct13
- 7Oct13
- 23Sep13
- 16Sep13
- 9Sep13
- 19Aug13
- 12Aug13
- 22Jul13
- 15Jul13
- 24Jun13
- 17Jun13
- 10Jun13
- 3Jun13
- 13May13
- 6May13
- 22Apr13
- 8Apr13
- 1Apr13
- 25Mar13
- 18Mar13
- 11Mar13
- 4Mar13
- 25Feb13
- 18Feb13
- 11Feb13
- 4Feb13
- 28Jan13
- 21Jan13
- 14jan13
- 7Jan13
- 17Dec12
- 10Dec12
- 3Dec12
- 26Nov12
- 19Nov12
- 12Nov12
- 7Nov12
- 29Oct12
- 22Oct12
- 15 Oct 2012
- 08 Oct 2012
- 1 Oct 2012
- 24 Sep 2012
- 17 Sep 2012
- 10 Sep 2012
- 27 Aug 2012
- 20 Aug 2012
- 13 Aug 2012
- Postponed to a later date:
- 30 July 2012
- 23 July 2012
- 16 Jul 12
- 9 Jul 12
- 4 Jun 12
- 7 May 12
- 30 Apr 12
- 23 Apr 12
- 16 Apr 12
- 9 Apr 12
- 26 Mar 12
- 12 Mar 12
- 5 Mar 12
- 27 Feb 12
- 13 Feb 12
- 6 Feb 12
- 30 Jan 12
- 23 Jan 12
- 16 Jan 12
- 9 Jan 12
- 2 Jan 12
- 12 Dec 11
- 28 Nov 11
- 21 Nov 11
- 14 Nov 11
- 7 Nov 11
- 17 Oct 11
- 03 Oct 11
- 19 Sep 11
- 12 Sep 11
- 29 Aug 11
- 2011 August 22
- 15 Aug 2011
- 8 Aug 2011
- 1 Aug 2011
- 25 July 2011
- 18 July 2011
- 20 June 2011
- 6 June 2011
- 16 May 2011
- 2 May 2011
- 25 April 2011
- 11 April 2011
- 4 April 2011
- 28 Mar 2011
- 14 Mar 2011
- 7 Mar 2011
- 28 Feb 2011
- 21 Feb 2011
- 31 Jan 2011
- 17 Jan 2011
- 20 Dec 2010
- 6 Dec 2010
- 29 November 2010
- 15 November 2010
- 25 October 2010
- 18 October 2010
- 11 October
- 4 October 10
- 20 September 10
- 13 September 10
- 30 August 10
- 16 August 10
- 2 August 10
- 19 July 10
- 21Jun10
- 14Jun10
- 07Jun10
- 26Apr10
- 19Apr10
- 12Apr10
- 29Mar10
- 22Mar10
- 8Mar10
- 1Mar10
- 8Feb10
- 1Feb10
- 25Jan10
- 18Jan10
- 4Jan10
- 21Dec09
- 14Dec09
- 30Nov09
- 23Nov09
- 16Nov09
- 09Nov09
- 26Oct09
- 19Oct09
- 12Oct09
- 21Sep09
- 31Aug09
- 31Aug09
- 24Aug09
- 17Aug09
- 10Aug09
- 3Aug09
- 27Jul09
- 20Jul09
- 01July09
- 29Jun09
- 22Jun09
- S Nair, MMC: Reproductive hormones, gastric bypass surgery, and weight loss
- Sunil Halder, MMC: fibroid disease vs. control, vs. vitamin D level
- Note: For both studies, quoting a margin of error for the primary quantity of interest would be more helpful than considering the power
- Frank discussed reproducible research policies of Annals of Internal Medicine and Biostatistics
- 15Jun09
- 8Jun09
- 1Jun09
- 18May09
- 11May09
- 04May09
- 27Apr09
- 13Apr09
- 6Apr09
- 30Mar09
- 6Feb06
- 13Feb06
- 21Feb06
- 27Feb06
- 3Apr06 Heather Burks
- 10Apr06
- 17Apr06
- 10Jul06
- 17Jul06
- 24Jul06
- 31Jul06
- 16Oct06
- 23 Oct 2005
- 13 Nov 2006
- 27 Nov 2006
- 12Feb07
- 20 Aug 07
- 7 Jan 2008
- 11Feb08
- 17Nov08
- 1Dec08
- 8Dec08
- 5Jan09
- 12Jan09
- 19Jan09
- 02Feb09
- 16Feb09
- 23Feb09
- 16Mar2009
- 23Mar2009
23Dec13
Heidi Silver, Director, Vanderbilt Nutrition and Diet Assessment Core
I would like to determine the probability that subjects with GERD (gastroesophageal reflux disease) revert from having GERD to not having GERD based on their reduction in total sugar intakes.- Recommend analysis of weekly data serially to predict probability of GERD in subjects having GERD initially
- Can use baseline variables then a different model with baseline + updated covariates
- For modeling a given week's GERD status consider baseline sugar consumption and most recent sugar consumption as two predictors
- Might also look at weeks until resolution of GERD
- Effective sample size is about 36 * 2 = 72 so could analyze perhaps 4 variables
Chris Fiske, Division of Infectious DIseases, Dept. of Medicine
- Changes in immunologic factors in pregnant women with HIV
- Using samples from 3rd semester and post-partem using samples already collected
- Vlada Melekhin worked with Cathy Jenkins; VM left VU; mentor Spiro Kalam
- Interested in tendencies for viral load to get an upward bump post partem; is it an immune response or cessation of good medical care?
- Limited by 14 events (viral rebound)
- Would be far more informative to have a continuous response such as viral load
- If a standard voucher could be $2000
9Dec13
S. Shaefer Spires, MD, Fellow, Division of Infectious Diseases
Plan to discuss an epidemiologic study (retrospective chart review) of outpatient central line-associated bloodstream infections (CLABSI) to develop and validate an outpatient surrogate surveillance definition against the traditional CDC definition. My project is an epidemiologic study of outpatient central line-associated bloodstream infections (CLABSI). We plan to develop and validate an outpatient surrogate surveillance definition against the traditional CDC definition. It is a retrospective chart review. My particular question is regarding maintaining the subjects in the collective pool once they have been determined to have an infection for the sake of having an accurate denominator when I go back to validate this surrogate definition. For the purpose of my project I am mainly interested in determining the numerator, i.e. the case of bloodstream infection and associated variables. However when I need to validate our new surrogate measurement, will I need to maintain these patients in the pool or should I go ahead and exclude them?- build prediction model of infection first. Have information on infected patient who came back to Vanderbilt. Could use the patients who never got admitted to any hospital as controls.
Jonathan P. Wanderer, M.D., M.Phil, Assistant Professor, Department of Anesthesiology
Would like to get input the feasibility of modeling neuromuscular outcomes in the postoperative setting. It may be helpful to reference the following site for discussion: http://vam.anest.ufl.edu/maren/roc.html- 3000 patients with the drug were assessed post-operatively.
11Nov13
Gurjeet Birdee, Assistant Professor, General Internal Medicine & Pediatrics
To deal with VICTR review:- A large amount of data is to be collected but there are no statistical analysis plans for how to make use of the data. The proposed two-sample comparisons are probably inadequate. Analysis of change from baseline is highly problematic as detailed in http://biostat.mc.vanderbilt.edu/ManuscriptChecklist. ANCOVA should be considered (better: nonparametric ANCOVA based on the proportional odds model).
- There was no justification for a sample size of 30 in terms of precision of estimates (e.g., treatment differences). The budget for statistical analysis is probably inadequate.
- Clinical trial of breathing techniques, related to autonomic tone
- Secondary: correlation between psychological and physiologic relaxation
- 4w intervention with run-in baseline training
- Assessment at 3 times
- Sample size 30
- Minimum sample size to estimate a standard deviation (for future planning) is around 48 (both arms combined)
- How to gain from having 3 times? Roughly speaking effective sample size with 3 follow-up measures is about 1.5n
- What about an interim analysis?
- With VICTR there is a possibility of getting project funded in chunks, operating in a sequential design
- Baroreflex data are available in healthy populations; adult healthy controls 9.4 +/- 0.7 SD
- If you had n1=n2=15, margin of error in estimating a difference in means (half-width of 0.95 confidence limit) is qt(.975, 28) * sqrt((1/15) + (1/15)) * .7 = 0.52, i.e. with a total n of 30 can nail down the true difference in baroreflex to within +/- 0.52.
- If multiplied the sample sizes by k, margin of error goes down by a factor sqrt(k)
- Covariate adjustment: age, weight, sex, meds
- Parametric analysis of covariance (ANCOVA) assumes transformation of Y is correct and assumes normality of baroreflex for fixed levels of covariates
- Semiparametric analysis making less assumptions: proportional odds ordinal logistic regression model
- Can extend to mixed effects proportional odds model for repeated measurements; or use the GEE type approach where ordinary prop. odds model is fitted to "tall and thin" stacked data (3 observations per patient) and adjustment is made for intra-patient correlation using the cluster sandwich covariance estimator
- How to deal with multiple secondary response variables
- Go on record with a strong ordering of the questions of interest, report results in that pre-specified order
- Don't need multiplicity adjustment if adhered to
- Cook and Farewell
- Alternatively do variable clustering or redundancy analysis to reduce the number of response variables (this is masked to treatment); related to factor analysis and principal components analysis
- Change from baseline: better to use ANCOVA or semiparametric ANCOVA
- Biostat budget up to and including manuscript 45 hours = $4500. VICTR supports $2000 + perhaps 1/2 of remainder
28Oct13
Jason Castellanos
- See 7Oct13
Jumy Fadugba, Allergy & Immunology
- VICTR voucher request - standard $2000 voucher is appropriate
Donald Lynch
- Estimated sample standard deviation for measurements between two time points: 4.192
- Did sample size calculation using PS
21Oct13
No clients
- Meridith Blevins and Tebeb Gebretsadik attended and no clients stopped by.
14Oct13
Jens Titze, Luis Beck, Clinical Pharmacology
- BP, hormones, repeated measures
- What is the relative contribution of various levels on BP?
- Outside vs inside chamber, BP and concurrent urine analysis for hormone levels. 11 blood 27 urine steroid hormones
- Combined in + out cross-correlation with BP; 11 measurements inside
- Two types of analyses:
- Cross-correlation (concurrent relationship between two continuous variables)
- simple if no phase shift; for small n may need to pre-specify the phase shift
- Longitudinal profiling (mean time-response profile allowing for rhythmic activity)
- characterize a single parameter (hormone) or compare two profiles; easy to account for baseline BP
- if use updated (concurrent or lagged) BP analysis more complex (cross-correlation or time-dependent covariate)
- Cross-correlation (concurrent relationship between two continuous variables)
- Have tried partial least squares; need to penalize for number of opportunities were given
7Oct13
Jason Castellanos, Resident in Research, General Surgery; Co-Chair, House Staff Advisory Council
- Presented data on VU day care use across 8 types of employees
- Showed how to get Stata to make 7 indicator variables using
i.varnamein logistic regression - Recommended dot chart with major categories Faculty, Staff, showing proportions and 0.95 confidence intervals
- Would be nice to have age distribution data for the 16 cells to do some kind of age adjustment
Revisit 27Oct13:
- Obtained demographics on all VU employees; requesting same for those using day care
23Sep13
James Lee VUSM II
- One record per visit
- Viral load, CD4, bmi
- Primary interest: reported marijuana use (MU) at that visit (count of use in last week)
- 7800 pt-visits (1000 patients); 6000 reported no use
- Have age, race, sex
- Possible worry: what causes MU to vary may cause weight to vary
- Have been using a mixed effects model in Stata (random effect = subject)
- May need to add to the model a continuous-time AR1 correlation structure in addition to the compound symmetric structure that random effects assume
- Some of the clinicians working on the project desire to simplify the analysis in various ways which were discussed and found to create far more problems than they solve
- Would be better to not assume a linear effect for MU; recommend a quadratic (add MU^2 to the model)
- Don't try to interpret the two coefficients; instead make a graph of MU vs. predicted Y
- To help understand the data, predict current CD4 then bmi using lags on the variables. For example, is the relationship between previous MU and current BMI much less strong than the relationship between current MU and current BMI?
- Consider patients having >= 4 visits, model effect on BMI of MU 6 months ago, subsetting entire analysis on patients with MU=0 currently or in past month
- Could include calendar time in model (in addition to age); but study has only 3y time span
- Square root of CD4, log of viral load
- Need to solve for which transformation of BMI makes residuals symmetrically distributed with equal variance across subgroups (and with luck, normality) (log?)
- May need quadratic in age also
16Sep13
Donald Lynch, Cardiology
Sample size:- research question: Among patients with severe aortic synosis, does percutaneous aortic valve replacement significantly change the proportion of patients with loss of hi-molecular weight VWF-multimer?
- background data: v-factor at T0 and T1 (1 month) and T2 (24 hours after procedure). Y/N loss of hi-molecular weight VWF-multimer. 62% of patients have loss under SOC. 100% at 24 hours (under diff, but similar procedure).
- With 60 individuals and 100% response, we will have 95% confidence that the true population estimate is in the interval 0.94-1.
- For 40 it's 0.91-1.
- Could look at precision of response for sub-groups (different baseline) also, if that's interesting.
9Sep13
Charles Phillips, Resident, General Pediatrics [Mentor: James Gay]
I have a data set that I would like to have some help with the analysis. I am not sure which test(s) would be the best to identify significance for my data. My data set contains general pediatrics patients admitted to the resident services from July 2009 to June 2012. I want to measure select patient outcomes before and after the resident duty hour restrictions implemented on July 1, 2011. Specifically I want to compare July 2009-June 2011 vs July 2011-June 2012. One of my questions is, given the fluctuation in patient volume at children's hospital should I break down the data into quarters or months for analysis? The specific markers I want to look at are the following:- 30 Day Readmissions (column E)
- Length of stay (column L)
- RCW Inlier (column M)
- Charges in 2012 USD (column T)
- Need to consider cost vs. charges, separating diagnoses present on admission from those that developed as complications during hospitalization
- Suggest fitting monthly trends on all outcome variables before the change and a separate trend after the change
- General statistical test would test whether the two curves are really one curve but allow for slopes/nonlinearity
- Need to code "errors"; do you analyzing them individually or in groups or by summing the number?
Celeste Ojeda Hemmingway MD, Assistant Professor, OB-Gyn, Assoc. Residency Prog Dir
I am planning to come to Monday's biostat clinic to get help on how to mine my dataset in SPSS. It's an educational project looking at an assessment tool and I want to think of opportunities I have to validate the tool I"m using. I will bring my SPSS dataset with me, but I suspect we will just get started on it. This is an assessment tool looking at evaluating resident surgical/procedural skills. I would like to validate the tool and look at potential ways to take out information. There is a rater and a proceduralist and they get a numerical score as well as a compositite assessment of competency. I would like to consider ways to validate it (inter-rater reliability - though this is tricky because only one rater present, categorical by year etc) and perhaps correlate the numerical score to the composite competency score. I fear this might need a little more explanation and I will be happy to bring the tool, examples, and the data file. Part of Masters in Health project (MHPE).- 5-point Lickert scales for skills assessment; overall competency scale; watch for lack of variability in ordinal choices
- Looking at April-June. New residents starting in July
- Can the survey instrument be shortened? How to validate it.
- Evaluators are uniquely coded; validation would be strengthened by using pairs where the evaluators are different
- Basic method of evaluation in the past: compare competency on one procedure with competency on previous and next procedure
- Literature has, for different procedures, summed the items and compared to global skills checklist
- Start with scatterplots and other graphs
- Is a hierarchical analysis needed because of nesting? Multi-level model needed?
- Basic statistical measure: Spearman rho rank correlation between one item (or sums of items) and global assessment
- Could assess relationship between years of experience and scores (individual procedure plus global)
- Can have a statistical model for resident scores where a smooth function of calendar time is included. Use actual date of evaluation.
- Other covariates: age, number of previous procedures done, etc.
- Try to lot all raw data
- Can scenarios help with validation?
- Look at variablity across evaluations for different evaluators; evaluators who vary the most may be the most discriminating
Susan Salazar, Assistant Prof, OB/Gyn, working with Eduardo Dias and Meghan Hendrickson. Mentor: Kim Fortner
I would be interested in meeting with a statistician about design study and statistical interpretation. My study involves the use of a hand held ultrasound machine and I want to demonstrate that it improves workflow (i.e. decreases length of stay) for women in our triage unit. I also want to show that it shortens the time of our "code" in labor and delivery (obstetrical emergency). I am collecting the data for these events for the months of Feb-May so I will have a baseline for comparison. So far, I have 36 women who received ultrasounds in triage from Feb-May. I'm thinking just a paired t test or possibly ANOVA, but I'd love your input. I will be applying for a VICTR grant as soon as I have the design study and statistical analysis framework ready.- Standard non-portable machine has a significant warmup time
- Length of time in triage is of key interest
- 2 types of randomized designs (individual vs. cluster vs. randomize so that a given day is all-in or all-out)
- Will remove part two (the staff satisfaction survey) due to lack of reasonable tool
- Will keep the resident OBET exploratory arm as a type of qualitative data collection that may lead to development of another study
- Estimated ~20 hours of biostatistical support from VICTR
19Aug13
Sharmin Basher, Clinical Fellow, Division of Cardiovascular Medicine
See http://biostat.mc.vanderbilt.edu/ClinicAnalyses#Sharmin_Basher_Cardiovascular_MeI am planning to investigate the effectiveness of supplementary written information given to women during cardiovascular disease prevention counseling compared to verbal counseling alone. I'm randomizing patients who are new to prevention counseling into an intervention arm (verbal counseling with written supplements) and control arm (only verbal counseling, no written supplements). Both groups will receive survey prior to the visit to assess their knowledge. The intervention group will receive a pamphlet emphasizing what is discussed verbally during the visit and the control group will only receive verbal counseling. Both groups will take the test again in 1 week to assess their knowledge. I am not sure what sample size I would need to determine a difference in knowledge. The survey I am using is a valid and reliable tool and is comprised of 25 questions. I've attached the paper that describes the development of the tool. On page 66, they mention in Table 2 the means and standard deviations. In order to determine my sample size, what SD should I use? I've calculated that I should have 20 patients in each cohort for a total of 40 subjects. Dr. Muldowney has asked that I randomize the groups by stratifying by patient education level and by the person providing the verbal counseling (there will be 2 people providing verbal counseling: Dr. Emily Kurtz and myself).
Stephanie Sohl, Department of Medicine
I would like guidance on conducting and interpreting a logistic regression (outcome is two categories that are nearly evenly split; N=191). Materials are in ~/clinics/general/sohl- Discussed treating more of the continuous and ordinal variables as continuous to increase power (age, education, duration of relationship, number of visits, etc.)
- Number of candidate variables (candidate d.f.) that can be "safely" analyzed (i.e., the fitted model would likely replicate in another similar sample): one rule of thumb is to have no more than m/10 candidate d.f. if m is the minimum of the number of events and non-events (91 events here)
- A data reduction method such as principal components can be used to concentrate a series of other variables into a score to see if they have an additional relationship with cha
- May need to pay special attention to remission status/timing, time since diagnosis
- Can also do empirical redundancy analysis to limit candidate variables (variable clustering or formal redundancy analysis)
- Rather than building 2 models with 2 different types of variables, may be beneficial to fit one model and to test groups of related variables in a "chunk test"
- If more than, say, 5 subjects are being deleted due to missing values on one or more variables, may need to do multiple imputation
12Aug13
Donald Lynch, Clinical Fellow, Dept. of Cardiovascular Medicine, Dept. of Medicine
Investigation of Mechanisms of Hemorrhagic and Ischemic Complications in Transcatheter Aortic Valve Implantation: Focus on Impact of Platelet Dysfunction and Atherothrombosis
- Protocol in ~/clinics/general/TAVIprotocol.docx
- A main outcome is GUSTO major bleed. May increase power/precision to use an ordinal bleeding outcome
- Access site bleeding can occur immediately upon removal of stent
- Will use CHAD scores, which characterize stroke risk in Afib patients
- Looking for pre-procedure biomarkers of bleeding risk, plus vW factor, platelet function, classic CV risk factors
- Logistic model to be developed to estimate risk in TAVI patients
- Also want to compare bleeding across 2 or 3 procedures (balloon valve/open heart surgery/TAVI)
- May be difficult to interpret out of context of the benefits of the various treatments
- To estimate sample size, need the dimensionality of candidate risk factors and distribution in the patient population of the bleeding outcome measure (assuming events are less common than non-events)
- If the outcome were binary, number of events needed is roughly 15 times the number of candidate risk factors
- Another aim could be to look at patterns over time of biomarkers esp. related to acquired bleeding problems due to chronic aortic stenosis
- Overall question to answer first: Is the goal to understand biology or to predict outcomes?
Consuelo Wilkins MD MSCI, Executive Director, Meharry-Vanderbilt Alliance
I'd I like to get some input regarding study design for determining the effectiveness of using the community review board as a method of obtaining patient-centered stakeholder input. You may know that the community review board is modeled after the VICTR studios, however; instead of academic experts, we use community experts. We think that this is a good model for obtaining patient-centered stakeholder input and would like to demonstrate that it changes the research. Our biggest challenge has been identifying an appropriate comparator. There are several issues:- We are unable to randomize the researchers to a control group. We have done 17 community review boards to date and all of the researchers have found this highly valuable. New investigators are unlikely to accept the control.
- There are no good alternative methods for stakeholder input. The other options- one-on-one interviews, semi-structured interviews, questionnaires, town hall meetings, and nominal group techniques- are resource intensive and would not be appropriate for all types of research.
- We considered comparing them to studios; however, the type of research being presented is likely very different and it may not be appropriate to compare.
- We also considered randomizing the researchers to a) an assessment of the research plans pre CRB, or b) an assessment of the research plans post CRB. The issues with this approach are - all of the projects are different and factors such as the researchers experience will likely impact the number of patient-centered elements in the pre CRB plans. Looking at only one measure as opposed to the change will not be useful.
Of interest is efficacy related to change in the research plan with respect to patient involvement and patient-reported outcome measures. One possibility is to have blinded impartial reviewers try to determine which of two versions of the 2-page grant summary is "pre" and which is "post". Reviewers could also rate the strength of patient/community involvement from the one they think is "post". It may be helpful to get input from Len Bickman. There may be some value in analyzing NIH/PCORI reviews.
22Jul13
Garrett Booth MD, Department of Pathology, Division Transfusion Medicine
- Background: Trauma Uncrossmatched Blood Use: Can we define inappropriate use of trauma blood in a number of ways?
- Definition of cohort -large database (over 10,000) of trauma blood use
- Purpose of the analysis: Risk factor identification of the use of unmatched blood
- Outcome variable: Use of unmatched blood vs. matched
- Set of risk factors: age, gender, type of service, time issued, time difference from arrival time to blood product issue, ABRh positivity.
- Anticipated work:
- Creating data which include one observation per patient, logistic regression (with one obs per pt data format) or GEE regression (with currently formatted as panel data). Repeated subjects are included however there is a unique individual encounter number.
- Descriptive and univariate analysis:
- Use trauma blood by year of administration
- Use of trauma blood by demographics such as the gender and age of recipient
- Use of trauma blood by type of service
- Use of trauma blood by issued time. What time(s) of day do we see the most frequent use of trauma blood?
- Time difference from arrival time to time of blood product issue
- Number of Units of blood requests by gender age, type of service and the additional variables above mentioned
- O positive vs. negative use
- Multivariable analysis:
- What are the factors that are associated with matched vs. unmatched blood use
- Recommendation was made to apply for a VICTR voucher for biostatistical assistance.
15Jul13
Rivka Ihejirika, VSM II, Vanderbilt Orthopedics and Health Policy Institute
- Analyzing data that involves a multirater Cohen's Kappa/Fleiss Kappa analysis
- Installed R irr package, computed Fleiss kappa
- See http://en.wikipedia.org/wiki/Fleiss'_kappa, http://cran.r-project.org/web/packages/irr/irr.pdf
Subjects = 9 Raters = 33 Kappa = 0.514
z = 66.5 p-value = 0 z=w z[] <- ifelse(w %in% c('ASA 1','ASA 2'), '1-2', ifelse(w %in% c('ASA 3','ASA 4'), '3-4', '5-6')) kappam.fleiss(z) Fleiss' Kappa for m Raters
Subjects = 9 Raters = 33 Kappa = 0.636
z = 52.3 p-value = 024Jun13
Diana Carver, Physics
- Simulated radiation dose profile vs real profile
- Simulated values have 3-5% Monte Carlo error
- Real profile used dosimeter
- Discussed Bland-Altman plots and showed that it doesn't matter whether take logs or not for this particular dataset
- Difference decreases with mean, so does variability
- Moderately strong effect of slice #
- Recommend showing 3 plots: (1) Bland-Altman y-x vs (x+y)/2; (2) x vs. slice and y vs. slice #; (3) y-x vs slice # (showed strong downward trend; can supplement with loess nonparametric trend line)
- Crude summary mean|y-x| (but varies with slice and (x+y)/2
17Jun13
Minoo Sarkarati, MMH SOM
- REDCap national survey of academic medical center, targeted at students
- LGBT disparities - feelings of discrimination, resources at school, staff to help
- Think about correlational analyses vs. absolute prevalence estimates (the latter is more harmed by non-response bias)
- Look at response proportion per institution vs. mean answer to each question
- Variable clustering will be helpful in looking at which answers "run together"
- Correlations: Spearman's rho rank correlation
- Descriptive statistics: quartiles, frequencies
- When estimating absolute means or proportions is appropriate: compute 0.95 confidence limits
Natalia Plotnikova, VMS Dermatology
- Prognostic markers - has been working with Li Wang
- Pts who progressed vs who did not progress in type of cutaneous T-cell lymphoma
- Wilcoxon-Mann-Whitney two-sample rank-sum test is for comparing two ordinal or continuous variables
- Fisher's exact test is for comparing two categorical (non-ordinal) variables
- Note: Fisher's test is conservative when compared with the ordinary Pearson chi-square test (P-values are too large)
- Another study- educational intervention pre- vs post-test score, delayed (1m) post-test to check that effect sustained
- Need delayed post-test on at least, say, 14 subjects in order to not suspect a non-response bias
10Jun13
No clients
3Jun13
Victor Nwazue, Dept of Med, Division of Clinical Pharm (PI: Satish Raj)
- Postural hypotension syndrome (POTS) [n=10 POTS, n=10 healthy; preliminary analysis, will have 26 POTS]
- May want to do a comprehensive analysis on 20 patients and test for interaction between treatment and disease status
- Can also test treat effect specific only to POTS within this combined model; has more error degrees of freedom so achieves a better estimate of residual variance and random effects variance
- If variance differ between POTS vs healthy than may be best to do separate analyses
- Studying POTS patients on special diets; randomized 2-period 2-treatment crossover design, 1-month washout period
- One phase: low salt, 2nd phase: high salt
- Does high salt increase blood volume and improve blood pressure etc. red blood cell mass, urine electrolytes
- Many of the measurements are daily for 6d while in CRC; volume, RBC mass, hemodynamics on 7th day (plus day 1 pre-treatment)
- Need to think about whether baseline should be ignored if doing a simple paired comparison
- Using mixed effects model
- Recommend mixed effects model with an additional correlation structure
- For singly measured variables (on day 7) can use Wilcoxon signed-rank test for paired data
- Could use a summary measure approach to reduced the 5 measurements to a single summary measure (area under the curve/slope/mean/median)
- Day 1 = baseline (pre-treatment) so really have 5 post-treatment measurements
- Bland-Altman plot [y = period2 - period1, x = (period1+period2)/2] needs to be flat and show constant variability across x
- Discussed several issues related to unblinded interim analysis that was not specified in the protocol/statistical analysis plan
- Can apply for VICTR biostatistics voucher for the final analysis (but not the interim)
13May13
Steve Deppen, Thoracic Surgery/Epidemiology
- Discussed nomograms vs. data entry screen -> predicted values from a model with confidence intervals
- See http://biostat.mc.vanderbilt.edu/wiki/pub/Main/FHHandouts/Dialog.pdf and

- Discussed bootstrap internal model validation in context of multiple imputation
6May13
Cecelia Thebald, MPH Student, VA Quality Scholars Fellow
To discuss my MPH thesis project. I met with Yuwei today and I think she may try to attend Monday as well. I am planning an interrupted time series analysis to evaluate the effect of a handover communication tool deployed a few years ago for patients transferred into VUH.- Efficiency and timeliness and cost-effectiveness related to handover
- Currently has one year of data before and 6m after transition. Major changes in April 2011; initial change 2010
- System was put into effect July 1 coincident with new house staff
- May be able to argue that new residents are working against the hypothesis due to inefficiency in ordering
- Look at previous year and see what happened July 1
- Many reasons to do patient-level outcome analysis
- Model: Y = a + b*POST + f(calendar time) with restrictions on f to not perfectly pre-ordain pre/post
- Perhaps better: Y = a + f(days since implementation) where f is allow to have a discontinuity at t=0 [but not force the discontinuity]
- f = cubic spline with no continuity restrictions; perhaps 5 knots with one of them being at zero; might restrict function to be continuous when t is not zero
- Can also estimate special contrasts for Y(t) - Y(0)
- One of the outcomes (load and interpret image from outside) is binary; consider binary logistic regression model
- General goal: Estimate Y with simultaneous confidence bands for the time effect
- Estimate 35 hours
Eric Thomassee, Cardiovascular Medicine Fellow
I want to look at door-to-balloon times in ST elevation MI (myocardial infarction). The standard of care at this time is to complete revascularization (placement of coronary stent) within 90 minutes of presentation to the emergency room. Other guidelines recommend revascularization to be completed within 120 minutes of presentation to the EMS. Multiple studies have shown improvement in clinical outcomes when "door to balloon" times are less than 90 minutes. It is difficult to estimate the effectiveness of EMS systems based on door to balloon times alone. Example:- Patient 1 presents to Nashville General and is transported to Vanderbilt for emergent cardiac catherization. Door to balloon time is 70 minutes.
- Patient 2 presents to Dixon/Horizon Medical Center and is transported via helicopter to Vanderbilt for the same indication/procedure. Door to balloon time is 70 minutes.
- Both patients have similar clinical outcomes
- EMS was more "effective" in transporting patient #2 because they travelled a longer distance but maintained similar door to balloon.
- n=800 transferred to VU since 2007
- Have eliminated false positives; using only patients who ended up getting a stent
- A general goal of quality outcome metrics: something to optimize that is based on modifiable parameters
- Initial step: enumerate all possible source hospitals/transfer patterns and count frequency of these occurences; will help determine how fine grained the analysis can be
- Compute descriptive statistics
22Apr13
No clients
8Apr13
Jun Dai, Division of Epidemiology
Dr. Karen Kafadar at the Department of Statistics, Indiana University-Bloomington strongly recommended you to me for helping us to address a reviewers comment on our manuscript. The issue relates to statistical power and the interpretation of bootstrap results. Would you be willing to give me your opinion? If so I will send you the relevant information from the paper and the reviewers comment on the issue?- Used the bootstrap, looked at overlap of confidence intervals for two predictor effects (recommended by reviewer, not a good idea), also looked at standardized estimates
- Bootstrap took into account twin pairing
- Also looked at whether 0.5 of statistically significant results
- Bootstrap provides no new information in this context
- Exposure = post-load glucose; analysis of attribution to glucose or to the common factor
- Standardized regression coefficient create several interpretation problems
- Main analysis frailty survival model to handle twins
- W has HR around 1.03 around [0.9, 1.1]; B has HR 1.15 [1.02, 1.30]
- If lower confidence limit = 0.7 then you can't rule out a reduction in instantaneous risk as large as 30%
- If in addition the upper limit >= 1.0 then the data are inconsistent with harm as well as benefit
- Need to look at upper and lower limits
- May not be able to conclude that W is not effective
- W and B are on the same scale, so could compute confidence interval for the difference in the two regression coefficient
- Given se(W), se(B), corr(W,B) regr. coef. estimates you can compute se(W-B coefficients) -> conf. limits for W-B, see if overlap 0 (anti-log=ratio of two hazard ratios, see if overlaps 1.0)
- Strongest conclusion would be if CL for B excludes 1.0 and CL for W excludes anything far from 1.0 (e.g., CL is [0.95,1.05]
- For W-B compute the contrast in X1 and X2 that is being tested
1Apr13
Heidi Silver, Kevin Niswender, Hakmook Kang
Analyzing and interpreting data from high fat intervention- Y=wt & body composition, insulin sensitivity, endothelial function
- n=144 women randomized to 4 different diets after 2w stabilization on HFD
- t=0 (n=144), 2 (n=134), 9 (n=99), 16w (n=91); no indication of different proportion of dropouts by the 4 tx
- Possible baseline imbalances on race and pre-diabetes
- Primary analysis would be hard to interpret if 0-16w weight loss is included in the model
- Need to always adjust for both baseline values of each response variable
- See how highly correlated weekly weight measurements are with follow-up cholesterol measurements
- Variable clustering of response variables can help understanding of how they move together; also redundancy analysis
- Can check variance stabilization and Bland-Altman plots to find optimal transformations of continuous response variables
- Consider an initial analysis of weekly weights vs. dropout patterns; can you use the whole weight trajectory (up until time of dropout) to predict likelihood of dropout?
- Example model: Cholesterol at 9w and 16w (mixed effects model) = Chol0 + Chol2 + Tx + week=16 + Tx*(week=16) + Wt0 + Wt2
- Contrasts of interest: week 16 effects (3 d.f.); then 9 week treatment effects (3 d.f.)
- Global chunk (pooled) test for any treatment difference at any time (combines Tx effects + Tx*time interactions; 6 d.f.)
25Mar13
Consultants: Ayumi Shintani, Frank Harrell
Shannon Mathis, Orthopaedic Surgery
Orthopaedic trauma literature allows 20% of loss of follow-up data in long-term outcome studies. A recent publication suggests that this '20% rule' threatens the validity of the results of the study. A discussion of statistical methods used to impute missing longitudinal data and issues that arise when imputing outcomes is requested.- Discussed BA Zelle et al: Loss of follow-up in orthpaedic trauma: Is 80% follow-up still acceptable? J Orthop Trauma 27:177 March 2013
- Confused problems with sample size and P-values in general with non-response problems
- Paper would have been different had original sample size been 100 times larger; with non-random non-response the quality of the result is solely a function of the number of survey responders
- Look at literature on non-replication of P<0.05 (e.g. Steve Goodman Ann Int Med)
- Keep in mind that a 1% loss to follow-up is fatal if you are estimating an outcome that is 1% incident and it is those cases who do not respond
Jordon Apfeld, Othopaedic Surgery. PI: M. Sethi
- Applying for VICTR studio on project in Nashville Metro middle schools; will lead to grant applications
- Violence esp. gun-related; AVB program selection (Aggressors, Victims, Bystanders); social competencies and conflict resolution skills
- Need to select impact evaluation tools; might also looks at school-wide disciplinary rates
- Two major approaches
- Cluster randomized trial (randomize classes); need at least 20 clusters and it's not recommended that you use one school as a control for another; i.e., clustering needs to be done within school and between schools; with enough clusters at each school can estimate overall school effects
- Assume the intervention works but we don't know how long it works; do longitudinal study of individual student tests to determine duration of effect
- Can randomize the follow-up time; each student followed once but will be able to relate timing of survey to survey scores to plot a curve of diminishing effects
- Discussed hazards of pre-post test designs
- Also watch out for seasonal variation
- Talk to Shari Barkin, Russell Rothman. For psychological scales talk to Ken Wallston or Warren Lambert or David Schulant, Cathy Fuchs
18Mar13
Maribeth Nicholson and Kathy Edwards, Pediatrics
Would like advice on appropriate statistical analysis for a planned prospective cohort study (and VICTR application)- Recurrent CDIF; multi-center study being planned; f/u 60d recur Y=0,1
- Later recurrence likely due to a different strain (new primary infection)
- Focusing on a specify IL-8 polymorphism
- Question about univariable vs. multivariable statistical tests
- Will need to find out if there will be any patients who are lost to follow-up before 60d; no intermediate contacts
- Exclusion of incomplete cases from analysis could cause a bias
- Can do a logistic model analysis of the probability of dropping out as a function of baseline characteristics; data will not allow one to see if there are post-baseline factors related to dropout
- Discussed whether patients are most likely to return to VUMC vs. an outside system
- A "look back" imputation of 60d status could help if there are post 60d assessments that are predictive of 60d status for those who had 60d status determined
- Expect n=200; 40 recurrences
- Limited ability to predict overall risk with effective sample size of 40
- Applicable rules of thumb:
- Need 96 patients to estimate the intercept in the risk model accurately
- Need 15 events per candidate risk factor
- Extending past 60d would add events; could also consider recurrent events to boost effective sample size a bit more
- SMS and email might help
- Synthetic derivative using BioVU: feasible if phenotype is accurately discernible from EHR
- Might entertain penalized maximum likelihood estimation (shrinkage) to adjust for all the non-polymorphism variables
11Mar13
Jill Pulley, VICTR, Erica Bowton, Frank Harrell: Social Determinants of Health
All, as part of the institution's efforts to ramp up Personalized Medicine initiatives, we have been gathering some preliminary data related to patient views on what defines Personalized Medicine and what is important to them for a personalized health care experience. We recently sent out a quick survey to address some initial questions, followed by some equally quick analyses (done by Frank Harrell). We want to do more with the data. We will go over the analysis of the survey sent to registrants of ResearchMatch.org, used to provide background information for a grant submission to the Templeton Foundation.4Mar13
David Young, Psychiatry
Protocol for treatment of withdrawal from b? ... and/or alcohol. A person is given a drug (phenobarbital) every hour and then stop getting when they reach a certain level of intoxication. The outcome is qualitative response. There are the following five types of responses are: None, Drwsy, Calm, Irritable, Euphoric, Confused. This outcome is recored every our as long as the drug is being given. Want to see whether the outcome correlates with a diagnosis of bipolar disorder. The diagnosis of bipolar disorder is given based on patient's history. Suggested summary: the mode of all responses per patient. Suggestion by biostat: look at the likelihood of having bipolar given the most frequent response. We don't have enough power (number of events is about 35 out of 100) to include any other adjustment variable. Requested to prepare the data in the following way and come back to the clinic. 1. Create the main covariate: calculate the mode of the response per patient (can be 1, 2, 3, 4, 5) 2. Create the outcome 1- bipolar, 0 - no 3. Use logistic regression with the outcome and the covariate mentioned above. See previous clinic notes at WednesdayClinicNotes25Feb13
Mick Edmonds, Pathology Microbiology and Immunology
- Came to Wed. clinic
- Need to ensure that VANGARD core is approved for VICTR charges
Discussion of FDR and propensity score and quantile regression for longitudinal data
Steve Deppen, Epi grad student
- Multiple imputation - interpretation of rates of missing information and variance inflation factors; looked at collinearity
- Significant update about released for the R Hmisc package aregImpute function that affects predictive mean matching
18Feb13
Yaa Kumah-Crystal, Fellow, Pediatric Endocrinology
Consultants: Ayumi Shintani, Frank Harrell, Pingsheng Wu, Meredith Blevins
I want to discuss the protocol for a study I am planning on conducting to determine whether adding patient photos to the EMR will decrease documentation error rates. I would like to the design for my research project and get feedback about the best ways to measure and subsequently analyze the data. We will define "errors" as mistakes resulting in the submission of a Pegasus ticket for correction. I am also trying to see if there is a way we can also capture errors from amendments made to charts that did not result in a ticket submission. I do not know that there would be a way to define or capture 'close calls.' And at those would not be as important to capture as the actual errors.- Discussion about proper denominator for error proportion
- Discussed problems with pre-post design
- Units inherently have different error rates; could randomize units within blocks or otherwise match on predisposition to error
Cesar Molina, Orthopedic Trauma
Consultants: Ayumi Shintani, Frank Harrell, Meredith Blevins
- Was here 14Jan13
- Sample size justification needed
- Goal is prediction to inform patient expectations
- Read 431 (1.98 procedures per patient) charts to find tibia fracture with an infection (n=86; 6.6 procedures/pt), 47 deep
- To be used on patients upon their first infection
- Possibly used penalized maximum likelihood estimation; can also be more liberal with candidate risk factors
- Need to penalize (shrink; discount) risk factor effects down to effectively 47/15 = 3 degrees of freedom (3 regression coefficients)
- Penalized proportional odds ordinal logistic model
- May want to consider counting amputation as the worst outcome; however sometimes it is the best option; or consider right-censoring at point of amputation
- Amputation is consider a reconstructive procedure and counts as an event as things currently stand
Stacy Banerjee, GI fellow
Consultants: Frank Harrell, Meredith Blevins
- Cardiomyopathy - common in cirrhotics but under-recognized; often found during surgery or when stressed by another condition
- Cirrhotic cardiomyopathy can be reversed after liver transplant
- Interested in diastolic and systolic dysfunction - how does severity of dysfunction correlated with severity of cirrhosis
- And then post-transplant - systolic dysf. may correct but diastolic dys. may not
- 150-200 patients listed for transplant; do 120-130/y; liver clinic several hundred referred for evaluation for transplant
- Want to use patients referred but not put on transplant waiting list, for controls (will not necessarily get transplanted)
- Quantity to estimate correlation between systolic dys and degree of cirrhosis; estimate prevalence of cirrhotic cardiomyopathy
- Spearman's rho rank correlation
- Showed correlation precision graph (vs. n)
- Interested in biomarker relationships with dys (e.g., troponin)
- Expect to enroll 6 pt/mo -> 72 pts; would result in a correlation margin of error of roughly +/- 0.25; 100 pts would yield +/- 0.2
11Feb13
Jonathan Wanderer, MD, Department of Anesthesiology
Consultants: Ayumi Shintani, Pingsheng Wu, Aihua Bian, Uche Sampson,Tebeb Gebretsadik
Study on cost and anesthesiologists. N=5500 data set with each observation including total cost and drug used. Plan on doing multiple linear regression representing anesthesiologist as dummy variable (200) and 250 surgeons. Question on approach on cost variability and how many variables to include in regression model.- General plan is to use a linear regression, fitting a linear regression with a continuous dependent variable, can include about 5500/15 variables. *It also depends on the complexity of the variables included. *Interested in R square, variation explained of the model. Recommend to include the physician (anesthesiologist) as random effect . Assessment of variation explained: Compare the model with physician data and model without physicians for what fraction is explained by the physician component. You can also adjust for other variables as fixed effects (degree of patients sickness). *Linear regression with cost as dependent variable will need to transform cost variable. Linear regression will not have a good fit and likely that assumption will be violated. Look at log transformation of cost variable. *Random effect discussion:recommendation to include physician variable as random effect. *Create two variables one for the anesthesiologist and the other surgeon and can be included as random effects. Can create combination category to assess the working of anesthesiologist and surgeon for example that when working together may reduce cost. Surgeon with more year of experience and anesthesiologist with more year of experience, include an interaction term (cross-product term) as well as random effect.
4Feb13
Zac Cox, PharmD, Nick Hagland, Cardiovascular Medicine
Consultants: Ayumi Shintani, Frank Harrell, Ben Saville, Uche Sampson, Tebeb Gebretsadik
We would like to discuss the trial design, sample size calculation, non-inferiority design, and get your expertise on any other issues we might be overlooking. Briefly, we are designing a trial comparing the standard intravenous administration of Drug A vs the experimental inhaled preparation of the same Drug A. Our outcome (if you agree) would be nominal value (yes or no) in achievement of a 20% improvement in blood flow to the body. Drug is milrinone: IV vs inhaled. End stage heart failure.- Classifying achievement at 20% will result in a huge loss of information, precision, and power. It is far better to analyze blood flow as a continuous variable
- Rather than a formal non-inferiority design, this would best be done as an estimation study, designed around the margin of error that will be achieved in estimating the difference of interest
- Patients are getting concomitant therapies such as diuretics
- Within confines of practice try to unify how baseline of follow-up measurements are made
- Main parameters: pulmonary capillary wedge pressure, cardiac index
- What is the non-inferiority margin? E.g., how much below a 20% improvement could be tolerated?
- Might think of this as a pilot study. Pilot studies can be used to
- show feasibility
- show that a large fraction of patients will agree to be randomized
- estimate variability so that a pivotal study sample size can be estimated
- refine measurements and data acquisition
- Point estimate of effect from pilot study can almost be ignored
- For a pilot study, 20 patients per group is likely acceptable
- What about adverse events?
- Analysis plan might ultimately be analysis of covariance with Y = post-treatment cardiac index, X = baseline cardiac index, with treatment also in the model
28Jan13
Erin Neal PharmD, MyHealth Team
Background: Center of Medicare and Medical Services. Pilot group of 3000 patients trying to improve their control of blood pressure. Have 80% of patient in physiological control and would like to get beyond 80%. Have an outcome as controlled vs. not controlled and risk stratification of subjects. 20% of 3000 patients have very progressive disease stage. Would like to compare controlled vs. not controlled and improve target for more severe patients. 1271 (2 and 3) higher risk score vs. 321 are uncontrolled. What are the characteristics that define the uncontrolled group. Outcome is defined by blood pressure.- Timing of measurements and study design: Cross-Sectional, measurement for each patient, with home and clinic readings to define outcome. Subjects are enrolled in my Health Team and monitored in outpatient basis. Outcome defined after eight weeks of enrollment in intervention. May want to use data prior to intervention of program to be able to see actual data, natural trend before the 8 weeks intervention.
- Use the raw continuous data, you will have a lot more regression power:
- Consider using blood pressure (bp) as a an outcome, continuous dependent variable and perform a multiple linear regression analysis. Given patients profile build a predictive model that provided estimated blood pressure. That will involve building two models, one for diastolic bp and the other one for systolic because they may provide different medical information.
- Consider using mean arterial blood pressure.
- Longitudinal model including every subject without limiting to "uncontrolled" subjects with dependent variable blood pressure at 8 weeks. Baseline value prior to enrollment in intervention program will be adjusted and include risk factors as well in regression model.
- Ordinal outcome normal pre-hypertention stage I and stage II based on published levels.
- Define covariates (risk factors) and examine missing data issue.
- Perform a logistic regression analysis with the limiting sample size of 321 for inclusion of risk factors. The minimum number of events divided by 10 as a very rough guideline on the number of predictors that you can include- With binary logistic regression there is high loss of power and information.
21Jan13
Albert Gandy, Alumni Developement
- Study: Aim to be more efficient in targetting patients in soliciting them for gifts.
- Would like to build a regression model in R for the propensity to give of patients
- Instead of sending 3000 solicitations and getting only 3 responses, the objective is to send to selected group that is more llikely to give.
- Define the dependent variable, outcome variable: Anybody who visited within 2012. N~300,000 with screening to exclude subjects that are not to be solicited. No restriction on income on this dataset. About 5000 gave some donation following their visit.
- Information that is collected (Predictors to be considered):age (dob), gender, congressional district, census tract information of zip code level income, specific email service provider, (ex. gmail vs. other email client services). Medical treatment received, surgery received and type. Frequency of visit per month. Type of solicitation if attempted before.
- How many subjects donated without solicitations?
- Points to review before building a regression model on dependent variable ( donated yes/no or amount) with predictors.
- Preparing the dataset in a format that allow analysis and thinking through the variables and which way you want them or keep the current structure is going to be very important. What kind of information will help solve the question and extracted out.
- Include multiple years of data if possible and include the year of study in the model.
- Subject with surgery in December in 2012 -check 12 month after whether they donated. Have they donated before and that could be potentially a predictor.
- keep the date of donation and can later extract the month of donation to look at by month
- Check biostatistics website for database creation and variables definitions.
14jan13
Cesar Molina, Orthopedic Trauma
Consultants: Ayumi Shintani, David Afshartous, Tebeb Gebretsadik, Frank Harrell, Ben Saville
- Retrospective study of number of procedures pts undergo when get infection after tibia fracture (n=86)
- Average of 3.3 procedures per person; max=9; 22 have no procedures
- Patients had to have >6m follow-up
- Is smoking, open vs closed surg, mild vs severe injury a risk factor for more procedures?
- 43a, b, c classification for severity of injury
- Also have available: diabetes, cardiac, renal, age, sex,
- Consider using a general comorbidity index - Elixhauser or newer
- driven by ICD9 discharge dx
- Weight/BMI?
- Role if initial antibiotic choice?
- Recommend proportional odds ordinal logistic regression or Poisson regression or negative binomial; lean towards last 2
- Secondary analysis: time to infection
- Follow-up is longer for patients having early complications
- May not want to adjust for variation in follow-up
- Think of those with short follow-up as having number of later procedures imputed to be zero
- 10 pts did not return when expected to; would worry if they went to another medical center (typical: patient doing OK but physician recommended they return in a month but didn't)
- Number of potential risk factors that can be examined against the number of follow-up procedures is about 75/15 = 5 if the variables are not combined into clusters
- Variable clustering can be used as a data reduction tool (blinded to # procedures)
- Can apply for a $4000 VICTR voucher; Ortho Trauma will need to provide a letter of commitment for $1000
Chetan Patil PhD, Biomedical Photonics Lab, BME
7Jan13
Alison Woodworth, Director Esoteric Chemistry, PMI
- Sepsis risk prediction with Medical ICU - biomarkers for early stages of sepsis
- Early treatment helps - need to differentiate systemic inflammation (SIRS) from sepsis
- Procalcitonin and CRP
- Alert for SIRS - retreived leftover blood specimens; can look at 2d before, plus after
- Sepsis = SIRS + infection
- 5 inflam. markers measured on day of SIRS trigger; logistic ROC 0.86
- HR, RR, gluc, other things added from EMR
- Next step - presentation to ED; won't dictate treatment
- Will compare sepsis risk score before and after treatment
- WBC and body temp have continuous U-shaped relationship with likelihood of sepsis
- Proposed n=200 training n=200 test assuming 0.4 sepsis
- Split-sample validation is often problematic when n < 20,000
- 100 repeats of 10-fold cross-validation, or 400 bootstrap replications will work better
- Need to automate modeling process
- Check overlap of information in markers (variable clustering, etc.)
- Still need to quantify added value of new markers
- Can develop various approximations to a full model
Yaa Kumah-Crystal, Fellow in Peds Endocrinology (working with Dan Moore and Ravi Matthew)
- Patients are intervened because of a rise in HbA1c
- Potential significant problem with regression to the mean
- May need a non-intervened group with HbA1c rose
- Changes in HbA1c over time; before-after intervention (worked with Wenli Wang)
- Intervention: regressing back to a simpler diabetes regimen
- Did A1c trend change
- Wenli did linear mixed model
- Add a nonlinear effect (e.g. using a regression spline) of time since intervention
- Analysis may be strengthened by adjusting for calendar time
- May need to log transform A1c (Wenli did this)
- May be able to get help from diabetes research resource
17Dec12
Robyn A. Tamboli PhD, Res Asst Professor, Dept. of Surgery, Abumrad Lab
Determine if we have done the following power calculations correctly.- Specific aim #1 (SGU studies): We hypothesize that SGU will increase after RYGB. Previous data from our lab using gastric and jejunal feeding tubes (mean ± SD, n=9) indicate that the GI tract disposes of 30.1 ± 7.1 g of glucose with gastric delivery and 40.7 ± 8.9 g with jejunal delivery. We propose that the liver is primarily responsible for the increase of 10g in GI-mediated glucose disposal after jejunal delivery. Based on z statistics, 11 subjects will provide a margin of error of 4.7 g in the SGU measurement with a two-sided type I error rate of 0.05.
- Specific aim #2 (EGP studies): We hypothesize that the decrease in HGP after RYGB will be accounted for solely by a decrease in hepatic glycogenolysis. Previous data in our lab (mean ± SD, n=17) indicate that HGP is 157 ± 46 mg/min before surgery and 114 ± 34 mg/min at one month after surgery. We propose that the 43 mg/min decrease in HGP is entirely due to glycogenolysis Based on z statistics, 14 subjects will provide a margin of error of 21 mg/min in the glycogenolysis measurement with a two-sided type I error rate of 0.05.
Matt Koleh, Cardiology Fellow
Study to reduce postoperative AFib. We want to prospectively apply predictive model on high- and low-risk patients. Different experimental interventions in the two groups. Incidence of post-op Afib and hospital length of stay are the primary outcome variables of interest. We need to be able to predict which patients are high risk so that only randomized high-risk patients are given amioderone treatment. Plan to enroll 220 over 2 years.
10Dec12
Melissa Wellons, Endocrinology
- Sub-clinical cardiovascular disease and early menopause
- Biomarker earlier in reproductive life sought; ovarian secretion; anti-malarial hormone
- Pericardial adipose tissue and calcification from CT; from CARDIA study of racial differences in development of CVD
- 1053 women; 962 had 2010 CT scan, another 91 had them in 2005
- Calc. detectable in 18% of women; would be advantageous to quantify within the 18%
- Looked at paper by Wildman et al on sex steroid hormones and increases in body weight. Used structural equation modeling.
- Beware of linearity assumptions
- Think about whether there is a limit number (especially one) of dependent variables where more traditional regression modeling (univariate or longitudinal) might be used instead
- Since sample size is fixed, may be useful to justify the sample size in terms of the expected margin of error (precision) for estimating the main quantity of interest (e.g., correlation coefficient or regression coefficient (slope if linear))
- Discussed correlation coefficient precision graph
- Can also think about 15:1 effective sample size:variables (really parameters ) ratio
- Can use the proportional odds model to account for "clumping at zero" of calcification, if we could get an estimate of the entire distribution of calc.
- Multivariable generalization of the Wilcoxon-Mann-Whitney-Kruskal-Wallis test
Scott L. Zuckerman, M.D., Department of Neurosurgery
- Related documents were saved in home directory
- In short, our project is asking the question of when to treat cerebral aneurysms that have recurred despite prior emoblization treatment. Our plan is to design a comprehensive survey of all different types of aneurysm recurrences and then poll 30 well known cerebrovascular neurosurgeons, asking them at what threshold, based on these clinical variables (i.e. 75yo, smoker, 10mm opthalmic aneurysm with 80% occlusion) that they would treat. I've attached a brief study protocol and at the end, 4 tables that include all our variables we would need to manipulate to get a useful answer to our question, and two useful background papers. Our goal is to publish our findings w/ the above quantitative, descriptive data mixed with qualitative, anecdotal data from the experts.
3Dec12
Susan Bell
- Related to PILL-CVD and health care utilization
- Almost 900 patients randomized - cardiac - pharmacy intervention Y=adverse drug events. Secondary: health care utilization
- 40% of patients >= 65; health literacy, depression. Interested in age vs. time to health care utilization (hospitalization, ER visits)
- Preliminary data for VPSD application
- Small problem with missing data (some work done by Ayumi Shintani)
- Around 15 potential predictors
- Files in
~/clinic/general/bell - Rough estimate of biostat needs 35 hours = $3500
Jonathan Wanderer
Using a dataset of 72k patients, were working a model that uses intra-operative data to predict unplanned post-operative ICU utilization. Ultimately wed like to be able to build a real-time data sniffer that can detect cases that may need high acuity post-op care.Ive attached the manuscript as submitted, which used a divided dataset and step-wise logistic regression to build the model. The reviewers requested a different approach (quotes below). Further reading tells me that the approach we used wasnt the best, and Id love input on where to go from here and whats the best way to approach these kind of problems.
Dividing a cohort into derivation and validation cohorts, although classical, is no longer recognized as a reference method by statisticians. As a matter of fact these two cohorts come from the same population. Moreover, it might suggest that an external validation has been performed which is not really the case. Usually more sophisticated techniques are proposed (cross validation using boostraping See Molinaro et al. Bioinformatics 2005; 21: 3301-7) and considered to be the reference method for appropriate internal validation.
In the methods, the cases were split into a training and validation dataset. I would question if the model development would be improved using some form of cross validation. This would best be decided using consultation of a statistician.
Files are under~/clinic/general/wanderer - Recommend Clinical Prediction Modeling by Ewout Steyerberg
- Recommend bootstrap or 50 repeats of 10-fold cross-validation
- Variable selection is usually unreliable
- Only 1% of patients were admitted to ICU so effective sample size is not huge
- Admissions to ICU were usually right after surgery
Robyn A. Tamboli, Dept. of Surgery, Abumrad Lab
We would like to compare the effect of ghrelin to worsen insulin sensitivity between obese and lean subjects. To test this hypothesis obese and lean subjects will undergo 2 hyperinsulinemic-euglycemic clamps (one with ghrelin and one with placebo in random order) to measure insulin sensitivity. From previous studies, we have clamp measurements without ghrelin on 3 lean subjects (13.63 ± 0.71 mg/kg.min) and 9 obese subjects (3.51 ± 1.03 mg/kg.min). A difference in responses of at least 1.5 mg/kg.min would be physiologically meaningful.- Current VICTR award - CRC study
- VICTR amendment to add lean cohort
- Power/precision can potentially be improved by correlating with degree of obesity rather than comparing 2 groups
- May be worth assessing effects using both a 2-group comparison and a correlation analysis
- Note that BMI may have a U-shaped relationship with insulin sens.
26Nov12
ShengHui Wu
- Try to compare lung cancer intensity between male (Y2004-2010) and female (Y1997-2010) , 140 vs. 50
- A cohort study (SWHS and SMHS)
- intensity is the total event number divided by person-years
- Had incidence rates standardized for age
- Already fitted a cox model on gender and other covariates (better to include age). Could report HR of gender and associated p-value. Assuming distribution of other covariates the same in male and female, adjusted rate difference between male and female could be derived from marginal rates of male/female and HR.
- http://annals.org/article.aspx?articleid=1389845
Torfay Sharifnia, GI
- Cell culture experiment. Control and several interventions. Experiments were performed three times. In each experiment, single measurement for each group. Sample size is 3.
19Nov12
Pingsheng Wu, Biostatistics/Medicine
- Asthma study with many data sources, problem with missing race from some sources where race is a very important variable
- Ewout Steyerberg had a paper utilizing the change in a regression coefficient when you don't adjust for another variable
- Used this change to incorporate partial information
- Context: updating a prognostic model where new data omitted a covariate
- Discussed role of sensitivity analysis
Yuwei Zhu
- Need prediction interval in Poisson regression
- See http://www.ucs.louisiana.edu/~kxk4695/Bin_Pois_PRI.pdf
- See http://www.math.chalmers.se/Stat/Grundutb/CTH/mve240/0809/files/lab5/lab5.pdf equation 13
- See http://www.google.com/search?ie=UTF-8&oe=UTF-8&sourceid=navclient&gfns=1&q=prediction+interval+poisson+regression
Meredith Blevins
- Interested in developing a tutorial on coefficient of variation, intracluster correlation, effective sample size
Yuwei Zhu
- Propensity score with more than 2 categories
- See http://www.ncbi.nlm.nih.gov/pubmed/8181125
- Need to look for a propensity interval that overlaps all 3 treatments
- Can sometimes use recursive partitioning to solve for which types of subjects are in non-overlap regions of propensity
12Nov12
Monique Foster, Pediatric Infectious Diseases Clinical Fellow
I am currently conducting a case-control trial and want to make sure I am analyzing my data correctly.- Match cases to controls with ratio of 2:1
- Used Stata.
- The response variable is Ecoli-caused diarrhoea. Exposure is Ecoli. E+&D+ 50, E+&D- 6, E-&D+ 150, E-&D- 94
- Could use conditional logistic regression model
Wes
- National ED visits; number of pneumonia cases pattern in 2006~2009. Periodic pattern except Oct 2009 (there is an abrupt increase)
- Usad poisson model to estimate rate ratio between Oct 2009 and other years
- Could include month, year as predictors plus Oct 2009 indicator (interaction). Could estimate relative risk.
Martha
- Try to design a survey about knowledge of Down syndrome children (?)
- Survey better last no more than 20 minutes
- Create a score matrix. Assign points to questions (scientific input)
Daniel Muñoz, Division of Cardiology
We have developed the attached survey as a tool for assessing the feasibility of a large clinical trial comparing an outpatient versus in-hospital noninvasive testing strategy for low risk patients presenting to the emergency room with acute chest pain. (We initially attended one of your clinics on August 15, 2012 to discuss trial design and issues relating to sample size calculations). We would be grateful for your team's feedback with regard to the survey, especially with regard to the questions that ask about physician comfort thresholds for absolute and relative risk differences (Questions 11-12).- Followup for earlier discussion
- Compare eff and safety of out and inpatient stress testing
- Survey of ED physicians comfort with certain risk thresholds for low risk ACS patients
- belief is that people are overtested
- randomized to 1) ED stress test (likely to be negative) vs 2) wait till 48 hour outpatient visit to do stress test
- possible that ED stress test may be more informative than 48 hour stress test (possibly!)
- Questions 11 and 12 is to get at 'would you participate?' rather than 'clinically significant difference' Advice is to make questions very concrete e.g., if the baseline risk is X% at what level of risk would you still be comfortable with (e.g. (X+.25)%?) What is an acceptable level of increased risk?
7Nov12
Jonathan Wanderer, Anesthesiology [follow-up]
The published models only include one set of beta values, and from the methods description I believe they are multivariable ('covariates were selected in a step-wise manner in a multivariable model'). It's possible I am not correctly interpreting their methodology; I've quoted the relevant sections at the bottom of this email. I pulled some cases at random and did a manual calculation which matched the automated calculation, which is to say that I've not yet been able to identify an additional calculation error. We've also removed cases with the 'self-fulfilling' codes and re-evaluated the performance of the model. Surprisingly, the discrimination doesn't change (AUC 0.965 -> 0.975). I've un-expectedly been given a non-clinical day tomorrow. I realize this is late notice, but if there's time/interest I'd be happy to share an update at the noon clinic tomorrow or Wednesday (slide deck attached).I've used the val.surv function to try to build a calibration curve for the length of stay prediction (predicts above/below median LOS), the results and R code are on slides 14/15. The curves continue to look funny. I'll try the 30 day/1 year survival curves next.
(from Sessler et al, 2010):
"'Our approach was to derive a measure of the risk posed by each patients comorbidities, jointly with the risk associated with each procedure. Diagnosis and procedure codes (ICD-9-CM) were used to generate the optimum covariate set for modeling each endpoint (LOS, in-patient mortality, and 30-day and 1-yr postdischarge mortality). The ICD-9-CM codes are hierarchical; therefore, it was possible to truncate the codes to a higher level to ensure consistency of the covariates across time to account for new codes and changes in code use (fig. 2). In successive iterations, covariates were selected in a step-wise manner based on the statistical significance of the covariates in a multivariable model (Stepwise Hierarchical Selection). Cox proportional hazards modeling was used to model time to postdischarge death and time to discharge.' Because the timing of the diagnostic and procedure codes during the hospitalization was unknown, logistic regression was used to model in-hospital mortality.
Description from coding algorithm: "Model the endpoint using the current covariate set. Cox proportional hazards modeling is used to predict time to post-discharge mortality and LOS, while logistic regression is used to predict in-hospital mortality. The set of resultant Mk covariate coefficients are βEnd Point, j with covariate means μEnd Point, j. The covariate means are zero for the logistic model."
A Cox or logistic model was used to estimate the hazard associated with each covariate. The initial covariate set included 1,951 variables used for the initial model of each endpoint. The limit of statistical significance applied to the model covariates was P less than 0.2 in the first iteration, P less than 0.05 after the second, and P less than 10?6 after the third. The fourth iteration was used to recalculate the final hazard ratios. The final model for each endpoint resulted in a different number of variables: in-hospital mortality,184; 30-day mortality, 240; 1-yr mortality, 503; and LOS, 1,096.
A risk stratification index (RSI) for each of the endpoints of interest was then developed, with RSI1YR, RSI30days, RSIINHOSP, and RSILOS denoting predictors of 1-yr, 30-day, and in-hospital mortality, and time to discharge within 30 days, respectively . The RSI value for each patient stay was calculated by adding the covariate coefficients associated with the patients procedure and diagnostic codes linked to the patient stay. The coefficient of each covariate calculated by the Cox modeling process was the natural log of the hazard associated with that covariate (or the natural log of the odds ratio change for the logistic model; ln(hazard ratioj). The total hazard arising from a particular patients diagnostic and procedure codes can be calculated as the exponential sum of the covariate coefficients associated with those codes. Total hazard has a non-Gaussian distribution; it is preferable, therefore, to use RSI as a risk-adjustment factor rather than the total hazard itself."Zhihui Dou, VIGH
- Extensive CD4 data from HIV patients in China
- Predictive survival model for AIDS patients; 15y followup
- Fitted Cox model, question about its correctness
- Is it necessary to include a time-varying covariate for CD4 in the model? Also have hemoglobin levels?
- May not be necessary to include age as time-varying
- Time origin is infection date; survival time from date of infection to death (assume all causes)
- Interested in predictive model from "now" to e.g. "now + 10 years"
- Would include CD4 and hemoglobin history (path) up to and including "now"
- Sometimes easier with parametric model than with Cox - see Herndon et al Statistics in Medicine Vol. 14, pp. 2119-2129
- Estimate cumulative hazard from covariate path - use analytic integration
- exp(- cumulative hazard) = survival curve given covariate path
- no software at present
- Predictions may assume that covariates are constant as of "now"
- Simpler approach: D'Agostino et al Statistics in Medicine Vol. 9, pp. 1501-1515 - repeated measures logistic model as applied to Framingham data with yearly covariate measurements
- May want to talk to Brian Shepherd who works with VIGH, and Dandan Liu - expert in survival analysis
- Also need to consider appropriate transformations of CD4, hemoglobin - or use regression splines
- Also interested in longitudinal model for CD4 count
29Oct12
Jonathan Wanderer, Anesthesiology
Im working on a project evaluating/validating two published risk score systems, the Risk Stratification System and the Risk Quantification System. Basically you input administrative data (ICD9 DX & PR codes, age/ASA/CPT, respectively) and get risk scores back (in-hospital mortality, 30 day mortality, respectively). Im in the process of generating calibration curves for those two systems using R, and the curve Im getting for the RQI looks as I would expect while the curve Im getting for the RSI does not. Ive attached the curves, the R code and the two papers for reference. I have de-identified data sets of 40mb total, which are a bit large for email. Would it be possible to meet with someone on Monday who might be able to help me understand the calibration results Im getting, or point out an error if Im making one in generating them?- Files are on clinic computer in
~/clinic/general - Constant term (intercept) was probably omitted when calculating the RSI
- Original model sorted diagnostic and procedural codes by odds ratios then fitted a multivariable logistic model; sample size was huge but still may result in overfitting; model omitted age
22Oct12
Tyler Reimschisel and Sunny Bell, Pediatrics
I am faculty in the Department of Pediatrics, and I would like to discuss the statistical methods that should be used in two education research studies that I will be conducting with the pediatric residents. One is for my thesis project for a Master¹s in Health Professions Education in which I will be conducting a quantitative and qualitative study critical thinking during team-based learning, and the other is for a simulation on difficult conversations that I am doing in collaboration with CELA. I would like guidance on the best statistical methods to use and power calculations. I have the designs well developed and am ready to submit the studies to the IRB once I have input from a statistician.- Parents of child with Downs' syndrome, 1st day - simulation
- 2w later Residents' clinic after heart and other specialists
- Feedback to residents, repeat, with a different couple
- How beneficial is this practice vs. just watch themselves on a video
- Secondary aim to look at gap narrowing - self-assessment vs. independent assessment
- Outcome self, SP (standardized patient), direct feedback assessment
- Will have a second senior physician score students in a blinded fashion from videos
- Quantity of interest: double difference: difference between study group and control in difference between day 2 and day 1
- Suggest computing confidence interval at study completion
- Think about how SPs are standardized in their ratings
- Consider using true analog scales (e.g., with REDCap Survey)
- Consider computing confidence intervals yearly in deciding when to stop
15 Oct 2012
John Koethe, Infectious Disease
- VICTR research proposal prepared with help from Bryan Shepherd. Came to clinic for quote of statistician effort.
- Pilot study will evaluate the effects of a novel drug on glucose homoeostasis and inflammation biomarkers. There are 5 time points with 12 patients.
- Suggest applying for 40 hours of VICTR biostatistician time
- First 20 hours free
- Will need letter from ID leadership confirming that home dept. will pay for 1/2 of remaining 20 hours ($1000).
Bennett Landmand, Biomedical/Electrical Engineering
- Study design and analysis for an inter-rater comparison study
- image quality score 1-5. Experts' assessments and naives' decisions. Two options (new and old). 10 naives.
- hypothesis is that naives' decisions are closer to experts' assessments using option 2.
- Concerned about the learning effect on naives' part.
- Crossover design with 1 week washout period. The naives read ten images in each phase using one option. Troy to make sure the same raters are not always paired together.
- Expert rater is gold standard.
- Calculate Spearman rank correlation (calculate confidence interval using bootstrap).
08 Oct 2012
Diane Levine, Medicine, Infectious disease
- Generation of regular (quarterly) reports for a CDC-funded project.
- Data base is in Excel format; may try REDCap
- Could ask for biostat support via BCC
Jessica Mouledoux, Pediatrics
- Compare two proportions in SPSS > x <- matrix(c(12, 28, 77336-12, 108604-28), nrow=2, byrow=FALSE) > prop.test(x) > x <- matrix(c(12, 18, 77336-12, 48348-12), nrow=2, byrow=FALSE) > prop.test(x)
1 Oct 2012
Petra Prins, Cardiovascular Medicine
- Question about log transformation in the context of group differences
- Sometimes motivated by requirements of statistical tests or to get a more evenly spread distribution (sometimes a heavy right tail dist. will be symmetric if take logs or square root or cube root)
- Sometimes treatment or predictors increase a response by a fold change (multiplication)
- How to tell whether you should use differences vs. ratios (fold change):
- Is the difference more stable or is the ratio?
- Which of the two gives you a standard deviation (or variance) that is stable across increasing mean levels
- OR: use a statisticial method that doesn't care if you take logs or not (medians, interquartile range, Wilcoxon, Spearman tests)
Claire Delbove, Pharmacology
- QR PCR (similar to RT PCR); outputs efficiency and CT; 2 primers (markers) may bind to wrong spot to give you some RNA that is not the RNA of interest; threshold is used to make a determination that what is below the threshold is background noise (mismatch, breaking or RNA, etc.)
- Normalized expression level = Efficiency ^ (Baseline - treated CT) / Efficiency ^ (Baseline reference from a different gene - treated from same gene as baseline ref); from a treated animal and an untreated animal
- 3 technical replicates from same cells (may need to ensure that the same threshold is used for all 3; can vary by gene/plate)
- How to calculate a measure of variability due to technical replicate disagreements
- Can compute SD of the 3 logged values and possibly antilog SD to get a fold change SD
- Can compute Gini's mean difference on 3 logged values: average absolute difference between any two observations 12 13 23
- anti-log to get Gini's mean difference-based fold change
- Dan Ayers usually comes to Friday clinic
24 Sep 2012
Bill Heerman, Pediatrics
Investigate effects of pre-pregnancy BMI and excessive peri-pregnancy weight gain on excessive infant weight gain (crossing two standard deviations on the growth chart, low power outcome) and wieght-for-length in the first year. Recommend to use a mixed-effects regression of outcome onto pre-pregnancy BMI and excessive peri-pregnancy weight gain.Jun Dai, Division of Epidemiology, Dept. of Medicine, VIMPH
For screening test, I have 21 pairs of identical twins, one co-twin died from disease A, while the other co-twin not. I have DNA methylation sequencing data. My study is to identify the differential expressed DNA methylation loci or regions using negative binomial regression. Assuming that fold change at log 2 scale is 1 as the significant level, standard deviation is .2, .5, and 1, what is the power for FDR=0.05, .1 or 0.2?For the validation test, assuming that 15 differential expressed DNA methylated loci are identified, fold change at log 2 scale is 1 as the significant level, the power is 80%, for FDR is 0.05 and 0.1, what is the sample size for non-related subjects?
17 Sep 2012
Amory Cox, Prattish Patel, Pharmacy
- See notes from 10 Sep 2012 here
- Vancomycin consult service managed by pharmacists vs. non-pharmacist managed (non-protocol; standard of care)
- Stop before dosing advisor implemented
- Patients are all over the hospital; possibly choose 2 units; 4 new consults/day; must be retrospective
- Change Y to proportion of appropriately drawn labs; consult vs. non-consult
- How to handle patients that are easy to get in therapeutic range, requiring few blood draws
- Those with few draws will have a low precision proportion
- Draw should be within 30m of next dose; trying to assess trough levels
- Might consider interval-censored data
- Need to have manuscript by June
- DIscussed VICTR developmental voucher and design studio
- Most of the work is chart abstraction
- Discussed blood markers
- Favor time-dependent consult patient status; assess impact of status change
- Need to capture updated patient condition at time of consult; understand all triggers for consult
- Suggest writing detailed protocol for criticism
- Try to measure renal function as a continuous variable instead of using acute renal injury Y/N
- Can use multiple spells/patient but doses are changed over time
- Time to "clinical success" may be worth pursuing; make sure can define for controls (those never entering protocol); watch out for informative censoring
Kiersten Brown Espaillat, Stroke Services Coordinator, Neurosciences, VUH
- New protocol that is sometimes used; 30-40 cases/month
- Goal is to receive t-PA before 3h window post-ischemic stroke; need to get a quick CT scan, lab, etc.
- Can pre-protocol be compare to post-protocol?
- Data, sometimes conflicting, from different physicians and different departments (ED, Radiology, ...); who to favor?
- Perhaps favor data recorded from nurses
- Protocol is supposed to be used all the time in ED for presentation of stroke-like symptoms; initiated 100% of the time but correctly perhaps 75%
- Lack of time by provider, provider not informed of protocol are major reasons for noncompliance to protocol
- If non-compliant protocol execution causes a patient to be excluded, this will create a large bias
- Think about the possibility of a provider stopping the protocol for a reason not described
- One (imperfect) approach is to plot monthly adherence % vs. monthly outcome
- Outcome could be time to t-PA, right-censored if t-PA never given
- Also consider NIH stroke scale
- Is there an effect of distance from patient's home to ED?
10 Sep 2012
Lawrence Gaines, Gastrointestinal Diseases
My purpose in coming to the clinic is to have the clinic staff estimate the amount of time/funds I will need to request from VICTR for a study of depression and Crohns disease that is part of a national longitudinal study of inflammatory bowel disease (see attachment) based in the Division of Gastroenterology and Hepatology, University of North Carolina. I have worked with Dr. Chris Slaughter on the original application and I will ask him if he can attend the clinic, too.- GI and Hepatology collaboration with UNC
- Internet self-report Crohn's disease and ulcerative colitis
- Relationship between depression and clinical course of Crohn's disease
- Is depression a risk factor for disease flare-ups?
- NIH PROMISE indicators used to measure depression - 4 items
- Retrospective cohort study
- Sample those in remission at baseline
- Look forward wm for flareup; subjective Lickert scale
- Interested in applying to VICTR for funding; need time estimate
- Have date of dx
- Short version of CDAI at study entry; don't need to classify as in remission
- Mannitoba IBD Lickert scale used for ultimate outcome
- Suggest writing statistical plan in the most general terms
- Suggest applying for 60 hours of VICTR biostatistician time
- First 20 hours free
- Will need letter from Psychiatry leadership confirming that home dept. will pay for 1/2 of remaining 40 hours ($2000)
Tokesha Warner, Alumni Relations and Fogarty International Clinical Research Scholars & Fellows Program
Matt Kolek, working in Darbar lab
- Beta receptor gene related to response to beta-blockers
- CRC study of pts with permanent atrial fibrillation (AF) off meds for a few days
- Atenolol, dose escalation to target resting HR and perhaps target exertional heartrate
- Carriers may have a more robust response to beta blockers, needing lower dose to achieve targer HR
- Y = dose needed, X = genotype + demographics, serum atenolol (variant not in PK pathway)
- 3 doses then double dose until reach target (and maintain)
- Suggest using the proportional odds model
- Use previous observational data, pooling over two genotypes, to estimate relative frequencies of the different doses
- Need VICTR planning voucher to do sample size/power calculation
- Apply for one voucher to be used for both final planning and actual analysis
- Recommend 50 hour voucher - first 20 free, need letter affirming support for remaining 1/2 (15 hours = $1500)
- Rather than power the goal may be estimation
Amory Cox, Prattish Patel, Pharmacy
- Vancomycin and MRSA; narrow window for efficacy/toxicity; monitored by blood level; risk of AKI leading to hemodialysis
- Pharmacokinetic consult service started
- Y = time in therapeutic window, adverse events (AKI, hemodialysis), # lab draws/dose
- Need to measure renal function as a continuous variable
- Secondary: mortality, LOS, microbiological cure (repeat negative cultures), defined daily doses (set regimen, how many doses required to get microb. cure)
- 2 groups (consult, non-consult)
- Consult pts examined from date of consult forward; are more complex pts
- Non-consult pts start at first dose
- Need to carefully characterize risk/complexity/time course
- Need to find some way to start the clock on the same day for both groups
- One approach is to use consult as a time-dependent covariate, and to add other time-dependent covariates that capture changing patient condition
- Discussed Stanford heart transplant analogy
- Need more discussion about "controlling for team"
- Need to understand consult service (Oct 2010) vs. dosing advisor (July 2012)
27 Aug 2012
Dandan Liu, Biostatistics
- Discussed biomarker problem - looking at added value of each of 2 biomarkers or combined; missing data on both markers
- n=500; 300 complete cases; 400 cases one-at-a-time
- See http://www.ncbi.nlm.nih.gov/pubmed/19364974?dopt=Abstract&otool=stanford
- Football plot should be considered
- Would be worth running a logistic model on the probability that biomarker j is missing given all the non-missing variables (including the outcome variable)
- One of the Y's has 0.05 incidence so number of events is about 25; would allow for including only 2 variables in the entire model
- 4-5 baseline variables other than biomarkers
- Concentrate on confidence intervals rather that P-values to avoid the tendency to make conclusions when none are warranted
- Feasible with smaller n: determine how well biomarker j can be predicted with biomarker k + other baseline variables
- Besides ordinary regression can entertain ACE (transform-both-sides generalized additive model)

20 Aug 2012
Trent Rosenbloom, DBMI
- Issue of group registration such that individuals register individually over the web but don't want to give one group a higher probability than another
- Groups can be identified up front
- Simple random sampling without replacement of groups, then include all members of selected groups
- As get close to target # participants you have to override the algorithm to select smaller groups rather than larger ones and ultimately to select individuals not part of groups
Jo Ellen Wison and Stephen Heckers, Inpatient Psychiatry
- Structured interview vs. clinical discharge dx
- Psychotic disorders
- Hospitalizations around the time the structured interviews were done
- Retrospective sampling with dx defined by the research team
- Do clinicians have a bias towards less severe dx than the researchers?
- Last clinic discussed advantages of serverity measures
- How to assess whether there is evidence for a shift of clinicians to less severe diagnoses
- Can consider patient characteristics (sex, race, age, etc.), psych comorbidities in influencing the shift
- Logistic regression model for Prob(clinical dx < res dx | sex, race, ...)
- Or ordinal outcome - by how many levels less severe were the clin dx? Proportional odds model
- Or Y = difference - positive or negative
- Overall hypothesis test - McNemar's test, or Bowker's test of symmetry (appears to be generalization of McNemar's)
- Confidence intervals for various probabilities
- Can access 460 patients if can deal with a large number of discharge dx; would require grouping of dx; for clinician dx only
- Hui Nian instant VICTR voucher - not including logistic modeling
13 Aug 2012
Prathima Jasti, Fellow, Dept of Med, Division of Diabetes, Endocrinology and Metabolism
Retrospective observational study using the synthetic derivative. The main aim of the study is to look at predictors of diabetes in patients who undergo partial resection of their pancreas. The sample size is about 700. I do not have much experience with statistics , so not sure regarding the model and the type of analysis needed. But based on previous literature, I think univariate and multivariate logistic regression analysis would be an appropriate approach. Is there a biostatics clinic that would be suitable for me to attend ? If so, what time ? I am looking for basics like power calculation, sample size and different analysis possible for my study. Also, I applied for VICTR grant and need to submit a quote for the desired expertise- Note: Univariate analyses are not very helpful usually, and the proper term is multivariable logistic regression analysis
- age, BMI, preop HbA1c being checked for availability, type of pancreatectomy
- Difficult to get estimate of proportion of pancreas removed; rough estimate based on anatomic landmark; only available for some surgeons
- Can make use of partial data using multiple imputation
- Y = HbA1c 6m postop; main covariate is preop HbA1c
- Enormous power gain by using HbA1c as a continuous variable
- Think about not excluding pre-op "diabetics"
- Blood glucose levels may be present when A1c is missing, which will help in the imputation of A1c
- Explore whether an abnormal A1c value can be inserted when a patient is known to be on an antidiabetic drug
- Some patients may come for a 4w postop visit and then not return again
- For any pt having at least one postop A1c or glucose measurement, suggest using all available postop data, with a longitudinal data analysis
- assume a smooth time trend in median A1c; when finished estimate median A1c at 6m
- Roughly 10 baseline variables of interest
- Goal: write a paper
- Estimated time 100 hours -> $10,000
- VICTR funds $2000 + 1/2 of $8000 -> need additional $4000 from home Division committing funds
Postponed to a later date:
Brian Wasserman, Fellow, Cardiovascular Medicine; Ben Shoemaker, Dawood Darbar
Consultants: Frank Harrell
- Replication cohort for a SNP that associated with ICD shocks
- Found an expanded replication cohort in BioVu
- Applying to VICTR for funds
30 July 2012
Mick Edmonds, postdoc, Pathology, Microbiology & Immunology
- Genes promoting lung cancer progression/metastasis
- Human samples from Lung SPORE; preliminary data from genes; interested in validation
- Around 2000 candidate genes; found 10-20 associated with cancer stage (using expression levels and not clinical stage)
- Used n=30 or so
- Would more predictive signal be found if analyzed all gene expressions in a joint multiple regression model (e.g., elastic net)?
- Multiple comparison problems - false positives, false discovery rate
- Kevin Coombs of MD Anderson is developing a method of screening gene expressions on the basis of their having a bimodal distribution
- Can pool with original data since stage not used in gene screening
- Suggest using Spearman's rho rank correlation between expression level and stage 1-4
- 42 samples would be required to estimate an unknown correlation coefficient to within a margin of error of +/- 0.3 with 95% confidence
- Need 64 for margin of error of +/- 0.25
- Request VICTR voucher for $4500
Sarah Nechuta, Epidemiology
- Comorbidity at dx vs. breast cancer outcomes
- Competing risks: breast ca death vs non-breast ca death (mostly cv)
- 80% die from breast ca
- Recommend book Extending the Cox model by Therneau & Grambsch
- Or submit small VICTR voucher for competing risk analysis with R with Li Wang
23 July 2012
Matt Kolek, Cardiology
- Studying pace maker device infection: antibiotic envelope vs. traditional care (n = 210 vs 609), 20 infections in whole data set
- Non-overlapping time periods
- Envelope = current standard of care for high risk patients
- Wants to assess if infection rate is lower for antibiotic envelope
- Initial analysis included univariate analysis which was rejected from the journal
- New analysis includes multivariate analysis, propensity score analysis with matching in SPSS
- Suggested time to event analysis and propensity adjusted sensitivity analysis.
Fernando Acosta (PI: Deborah Jones from Dept.of Peds)
- Patient population: Subjects with HSP nephritis
- Primary hypothesis: 6 month urine protein excretion values are associated with long term outcome (GFR)
- Urine protein excretion values are obtained at 3,6 and 12 months and GFR has a lower limit of detection.
- Estimated 40-60 hours of work and suggested applying for a VICTR voucher
Tolu Falaiye, Pediatrics
- Time to event analysis, works with Ben Saville.
16 Jul 12
Brendan
- ~ 250 participants in a social program. Reception invitations sent to participants over last four years. 2/3 respondents completed an evaluation of the program (survey) at reception. 28 total respondents.
9 Jul 12
Melissa Powell, Shelly Anglin, Sarah Dawson, VUH - 8
- Interested in patients 'Fall' and reasons behind this. Patients are very heterogeneous in background and illness.
- Want to develop risk assessment based on existing data.
- In June 2012, ~13 falls and several near falls.
- Want to determine if/when falls were preventable.
- Consider collecting data on: SES, admission diagnosis, frailty (serum albumin, weight), ultimate result of fall (degree of harm), history of falls (count).
- Missing data is one concern.
- Aim to minimize missing data.
- Statistical models will exclude patients with missing data unless methods are used, such as multiple imputation.
- Fallers tend to be those individuals that desire independence, how measure this in VUMC patients?
- Occupational/Physical therapy have tools like this (propensity to fall).
- Might be biased if collected post-fall, any way to assess independence at intake?
- Ultimately, if you want to develop a model predicting risk of fall, need data on non-fallers in same units.
- Current proposed data collection supports hypotheses concerning reasons why people fall, conditional on falling.
- Reliability of data based on observer variability -- Do nurses agree with each other? Does patient and nurse agree?
- Currently, there is a huddle of 3 individuals who come to a consensus, could consider collecting information separately to assess reliability (interrater reliability analysis).
- Could consider recruiting those who are at high risk of falling (based on admission history), then compare those who fall with those who do not fall.
- Can get the association between unit characteristics (e.g. staffing) and number of falls (without adjusting for history/risk). Sacrifice ability to investigate patient characteristics.
- Dan Byrne is working on pressure ulcers and re-admission risk -- consider contacting him -- experienced in health services research. Also, consider contacting VICTR for a studio.
4 Jun 12
Matt Semler, Dan Stover - see 30 Apr 12 below
Melissa Powell, Clin Educator 8th floor
- Pre- and post- intervention data; rescus. events; simulation
- Survey of how well people liked the simulation training, then 20 records on codes on 8th floor and another floor
- Residents rotate q6w
- Does the education need to be continuous? Is it effective in enhancing team communication during real code events; other team behaviours e.g. team leader identified; clear language; no way to capture data from a disinterested party
- Survey sent to 3 people involved in the code, after the code; different 3 people each time
- Concerns about self-assessment and objectivity
- What about using objective code outcomes (e.g., time to shock)?
- Can audio recordings be used in the future?
Drew Watson, Pediatrics Resident
- African American children 9-14 y.o.
- Metabolism and exercise capacity: sickel cell anemia vs. controls (similar on anthropometrics, gender, puberty); N=30 in each of the 2 groups
- 24h metabolic chamber; rest + exercise; 3 occasions 1y apart; 3 24h visits
- VO2max, total energy expenditure compare 2 groups; compare changes over time in the two groups
- Which physiologic variables (hemoglobin, fat free mass, sex, Tanner puberty stage, age) are predictive of exercise capacity and resting metabolism (energy expenditure)
- Main analytic tool might be multiple regression and generalized least squares for longitudinal data; interested in effects after adjustments for other variables; can test for difference in two slopes among other things
- Could do an indirect analysis - see if SCA relates to outcomes after adjusting for the manifestations of SCA
- Sample size to be adequate for a multivariable analysis in the sense of the model being reliable: 15 times as many subjects as candidate variables
- Works with Mac and has worked with Ben Saville
7 May 12
Leanne Kolnick, Hematology/Oncology
- Radiotherapy, head & neck cancer
- Validate 3 aspects of evaluation tool related to oral symptoms: dentist vs. patient-reported
- 50 patients; 1 dentist
- Dentist evaluation is the gold standard
- Some items Y/N, some are counts, many 0-10 never-always
- Need to decide on degree of granularity with which to ask questions
- A good approach for analyzing the strength of the relationship between the response to one question and a dentist's response to one question would be Spearman's rho
- UCLA site for helping learn SPSS: http://www.ats.ucla.edu/stat/spss/
- Graphical depiction: http://stackoverflow.com/questions/5453336/r-plot-correlation-matrix-into-a-graph
- Also consider redundancy analysis
30 Apr 12
Laura Wilson, Hearing and Speech Sciences, mentor: Dr. de Risthal
his retrospective study is designed to consider the relationship between demographic, biographical, and medical variables and quality of life (QOL) at 3 months post traumatic brain injury. Data will be collected from the records of individuals who were admitted to the Trauma Unit at Vanderbilt University Medical Center (VUMC) with a positive head CT and were seen for follow up at the Comprehensive TBI Clinic at VUMC approximately 3 months post-injury. Approximately 100 patients meet these criteria. Demographic and biographical variables that will be considered include initial GCS score (categorical- mild, mod, severe), age at time of injury (continuous), sex (categorical-male,female), insurance status (categorical- public, private, none), income as determined by zip code of primary residence (categorical in 10,000 increments), educational attainment prior to injury (categorical- less than hs, hs or equivalent, greater than hs), race (categorical), and premorbid employment status (categorical). These variables were selected because of their relationship with other measures of outcome after TBI, including functional, health status, and global outcomes. QOL will be indexed in terms of score on the Quality of Life After Brain Injury (QOLIBRI), which is administered to all patients in the follow-up clinic. Six subscale scores and one total score will be determined by participant responses on the QOLIBRI. Differences in the populations of those who follow up with the clinic and those who were eligible but did not follow up will be identified in terms of the same variables. The major contribution of this study will be the identification of possible predictors of health-related QOL in the acute stage of recovery. At 3 months, many individuals have returned home, stabilized medically, and begun participating in therapy. The results of this study will help contribute to the knowledge base related to QOL outcomes and can thus help build a case for the appropriate allocation and distribution of resources, as well as improved education for families and survivors of traumatic brain injury.- age, race, income from zip code, sex, Glasgow coma score, education
- Y = QOL score - total + sub-scales
- Important to use GCS as a semi-continuous variable
- For education need to assign years of education
- Redundant variables not a problem - can use a chunk test to combine effects of competing variables
- Important to pre-specify interactions because there are so many possible interactions. E.g. GCS and sex
- Recommend 15 times as many patients as there are variables in the model
- Think about inclusion of an injury severity score in addition to GCS, or CT scan injury extent
- Recommend proportional odds ordinal logistic model (especially for subscales)
- Need to assess prop. odds assumption
Matt Semler, Internal Medicine (with Brian Christman, Daniel Stover)
- Hypothesis: Traditional Mosby measurement of RR is lower than what's put in chart
- Working with residents at other academic medical centers; sample all on one day, approx. 1500 patients
- Vital signs in hospitalized internal medicine patients
- Respiratory rate measured manually, others are automatic; RR of 20 overrepresented
- Look at agreement with chart, choosing measurements at closest (or most recent) times to when resident measures
- One good summary measure is mean absolute discrepency between two measurements
- Might also plot the discrepancy vs. the time lag between the two
- Sample size justification: may be best to think in terms of precision and compute the margin of error (e.g., half-width of confidence interval for a mean absolute difference) after the data are in
- Could get a confidence interval for the difference in Prop(RR=20) and midpoint of Prop(RR=19) and Prop(RR=21)
- See if there is any value in randomizing the duration of RR assessment
- 4Jun12: Can look at disagreements between two types of measurements vs. time lapse between the two (secondary analysis)
- Now applying for VICTR funding
- Corner cutting from doubling 30s readings
- Compare proportions even vs. odd; more interesting to check multiples of 4
- Does Benford's law apply?
- Follow-up projects, e.g. morning reports dating back before EHR
23 Apr 12
Pam Hull, Medicine
- Needs to confirm statistical analysis plan of a manuscript
- Suggest applying for $2000 Voucher
Samir Aleryani, Pathology Lab Medicine
- Primary endpoint: number of attempts; secondary endpoints: quality of blood drawn, operator's satisfaction
- Pilot study to estimate effect size: 25 patients in each group; 10 operators using both methods
- All the operators will have been trained to use the new device
16 Apr 12
Jo Ellen Wilson - Psychiatry resident, mentor S. Heckers
- Presentation and etiology of psychotic disorders
- Accuracy of discharge diagnoses at discharge from psych eval
- 400 pts, in research study; reviewed all charts to see who as admitted to psych hosp; 1/2 had, some multiple (up to 20) over past 6y
- SCID - structured clinical interview 5h/pt done by research assist done close to hospitalization
- Compare SCID psychotic dx to discharge dx
- Collected comorbid disorders, age, sex, dx at other hospitalizations
- SCID includes confidence ratings, and perhaps other information that could be used to assess tendencies for disagreements between SCID and discharge dx
- There's some severity measures also; can be useful in analyzing close calls
- Need to measure stabillty of clinical dx over time
- So far have calculated the average number per patient in count of disagreements (discharge dx only)
- Possibly useful statistical model: binary logistic regression model for the probability of clinical dx as a function of SCID diagnosis, age, sex, possibly adding severity measures
- There may be a need to account for clustering (one physician seeing more than one patient in the study)
- Ability to do more in-depth analysis depends on the number of subjects available
Samir Aleryani, Pathology Lab Medicine
- Device evaluation: vein visualization - does it make an improvement vs. standard blood draw
- Two-group parallel design; 0-17 year old, stratify further
- Goal: 800 patients, 8 groups
- Y = # needle attempts, patient satisfaction (limited to 3 for one operator, otherwise turn to most experienced person nearby); quality of specimen (hemolyzed vs. non); time required to obtain an apparently OK sample
- Pilot study 25 patients in each of 2 groups
- Patient satisfaction needs to either be using a validated scale that has at least 10 levels, or should use a visual analog scale
- Will not mandate experienced operators to be used during the study
- Worth considering whether an operator should be restricted to only use one modality even if she deals with > 1 patient in the study
- If operators treat > 1 patient, should record the sequential patient number so can assess learning curve
- Each operator needs a unique ID number that should be captured in the study database
- Primary statistical model for # sticks (one stick will dominate): proportional odds model (handles any marginal pattern, heavy ties)
- To estimate sample size need: odds ratio not to miss, proportion of 1, 2, 3 sticks
9 Apr 12
Edward Powers; PI: Kevin Niswender
- VU football linemen vs. non-linemen, n=25 in each
- Metabolic syndrome
- Various indicators plus measure of oxidative stress
- May be useful to do a multivariate analysis by inverting the model to predict the probability of being a lineman as a function of the whole set of measurements
- May need to do redundancy analysis or variable clustering to reduce the number of predictors; unless the signal:noise ratio is high it can be dangerous to try to model more than 1/15th as many variables as you have cases (e.g., linemen)
- Dietary recall, anthropomorphic measures
- Concern for non-random volunteerism; compare with roster data
David Lubinski, Kylie Beck, Psychology and Human Development, Peabody
- Several hundred 13 year olds, SAT math and verbal scores
- 600 kids have spatial visualization measures - 3 dimensions: vis, quantitative, verbal
- Follow-up for degrees achieved, choice of fields
- See if raw data can be shown; jittering and use of color can help
Jacinta Leavell, MMC Public Health
- Survey: Barriers to accessing oral health care for immigrants
- Will also determine actual access to oral health care
- Characterize frequencies of individual barriers, cluster barriers that occur together
- Simplest way to judge the adequacy of a given sample size: margin of error for the estimate of a single proportion
- Margin of error = half of width of 95% confidence interval
- See https://data.vanderbilt.edu/biosproj/CI2/handouts.pdf p. 51
- Margin of error = 1.96 times the square root of 1/4n; n = sample size in one ethnic group
26 Mar 12
Genie Hinz, Postdoc Biomedical Informatics
- Case-mix adjustment - how to define the sickness of a physician's population
- Considered various comorbidity indexes
- Most are for short-term and fairly sick patients
- Sei Lee 2006 JAMA 12-point survey, includes functional status; dev 11,000 test 8,000 patients
- Inception: visit between 9/1/09 2/7/10
- Excluded patient if the visit during the enrollment period was not with the physician that they mainly saw during later follow-up
- Exclude patient if <2 historical visits with index physician
- Need to use a high-resolution plot relating predicted Lee risk to observed 2-year mortality
- requires special methods if have censoring (variable follow-up) otherwise can use straight loess estimator
- Currently have a serious bias in estimating 2-year mortality due to differentially determined mortality status
- Check follow-up date cutoff; used Kaplan-Meier estimates in table
- Used only physician-patient dyads
- Quantification of added value of functional status: plot distribution of predicted risks ignoring functional status vs. risks incorporating functional status
- Pencina method
- Cox model likelihood ratio test for added value of fctn status
- Avoid binning
- Look at George Stukenborg's papers (e.g., one on pneumonia)
- Look at re-including excluded patients to increase # deaths for some initial re-modeling
12 Mar 12
Tolu Falaiye, Peds GI
- Pilot smart phone app usage in kids enrolled in transitional clinic.
- App give basic info, alerts for meds
- Baseline, 3 month, 6 month follow-up looking at knowledge, compliance (adherence scale, pill counts, pharmacy refill), QoL
- Compliance is measured on 8 point scale
- 10 kids with app and 10 kids without
- Use PS to find detectable alternative for given scale and standard deviation (from pilot data)
- For modelling, rule of thumb is 10-15 events per parameter. * Feasibility * Another option is to plan the analysis and determine the number of parameters it will take to estimate the model with appropriate adjustments.
Meghana Gowda and Lara Changkit, Gynecology
- Interrater variability for vaginal mesh complications.
- Kappa coefficient with descriptive analyses
- VICTR funding suggested for biostatistics support is $2000.
- For the proposal to be funded, will need sample size justificaiton * Consider precision of Kappa statistics within subgroups.
5 Mar 12
Jessica Toste, Jenny Gilbert, and Don Compton, Special Ed, Peabody
- Young children (N=130) are treated with special instruction for reading. 2 sets of classification: responsive/non-responsive. Want to correlate these with other measures.
- Research Question: Are the cognitive/reading related measures different for non-responders according to classification 1 versus classification 2?
- Consider clustering based on four continuous achievement outcomes to find maximum distance between groups.
- To detect association between treatment and multiple responses: consider flipping treatment as outcome and use mixture of responses in a binary logistic model.
- Two-group comparison where groups overlap?
- Non-linear principal components
- Redundancy analysis -- might be more interesting if more responses. What non-linear combination of the responses predict the remaining responses?
- What are the group differences across both classifications?
- Consider a model with likelihood function using a mixture of paired and unpaired T-test (specify which subjects are paired).
- Generalized least squares -- mean model where each person has two rows of data
- Ordinary least squares with Huber-White sandwich estimator
- Mixed effect model with random effect for pair
- Or try doing a bootstrap of the difference (again must consider pairing).
- Consider plotting and calculating the confidence interval of the difference.
- Consider a model with likelihood function using a mixture of paired and unpaired T-test (specify which subjects are paired).
27 Feb 12
Amanda Back, Radiology
- Three distinct junctures ("geometries") of two major arteries (tuning fork, walking, lambda). Would like to investigate the association between these shapes and aneurism. 2 of 15 subjects did not fit in the three distinct categories.
- Concern that the "visual" classification is subjective, it is possible that there are dimensions to measure to drive the classification:
- Bifurcation/confluence angle, relative diameter, flow
- Another alternative is to use the raw data to predict outcome (not categorizing geometry but using the geometric measures instead)
- Some opinion that categorization by trained radiologists with high interrater reliability might still be useful vs. data driven classification.
- Sample size --- what number of images need to be looked at to determine the frequency of geometry occurrence?
- First step may be determined by precision of estimate (proportion+-half-length confidence interval)
- Second step will be a case-control study of patients with aneurism or other outcome.
13 Feb 12
Matt Kolek, Cardiology
- VICTR funding -- case-control cohort: 1) differential risk of infection (binary outcome), 2) risk factors in control (with only 25 infections, will be difficult to look at many risk factors recommend ~10 infections per risk factor [parameter]), 3) CEA.
- Plan to publish results.
- Suggested request $6000 for biostatistics support (first $2000 sponsored by CTSA, $2000 will need to be matched (total $4k).
Carline Harriott, Glenna Buford, Sean Hayes, EECS
- Victims to triage in first response (human/human vs. human/computer). Outcome: physical workload.
- Outcomes: continuous measures, counts, likert subjective measures Predictors: group and triage level.
- MANOVA will emphasize outcomes with maximum separation for variables on right hand side, though may not be direction of interest.
- If only one grouping variable, use group as 'outcome' and predict group membership. Still testing for association between group and measures. More difficult with more than one grouping variable.
- One ANOVA per measure is easier to interpret.
- Triage case is repeated for each group, so need to give consideration to repeated measures (consider mixed effect model -- generalized least squares).
Henry Ooi, Julian Noche, Cardiology
- Prospective systolic heart failure associated with exercise capacity. Some evidence that RV function is better predictive of exercise capacity. Echocardiogram stress test. Predictors include 6-8 variables, outcome is VO2max.
- Potential truncation problem for people who cannot complete test.
- Post baseline exclusion of early quitters might hurt interpretability. Consider an outcome that can be measured for all patients? Concerns for reproducibility of other tests.
- So then consider anaerobic threshold, if very low, perhaps treat VO2max as very low, then conduct a rank analysis. That is, treat VO2max as ordinal.
- Power/sample size depends on signal to noise ratio. For patient data, typically 15 subjects per parameter. For 15 parameters (slopes, regression coefficients), you would need 15x15=225 subjects. Even adjustment variables count. May need additional parameters for complexity or interactions. Solutions: 1) large study, 2) reduce right hand complexity (e.g. mean arterial BP, principal components, propensity or cluster scores). Redundancy analysis: if all hypertensive patients are older then don't use both in model ( requires pilot data).
- Potential truncation problem for people who cannot complete test.
Joshua Warolin, Pediatrics GI
- Energy expenditure and weight gain in adolescents in prospective cohort study (n=150 w/baseline, pre-puberty)
- Patients may dropout at 3 years (post-puberty, no interim time points) -- hoping for 75% retention.
- Sex, gender, race, expenditure (pre-puberty), BMI/body fat (pre- and post-puberty).
- Plan is to publish
- Suggested request $4000 for biostatistics support (first $2000 sponsored by CTSA, $1000 will need to be matched (total $2k).
Marguitta White, Genetics
- Effect of African ancestry on AEs. SNPs to predict global ancestry (% AfAm % CaAm). Clinical collaborator wants to see lower 10% and upper 10% of AE incidence with formal comparison (extreme phenotypes). 50% of patients had ZERO AE.
- Will likely involve a decrease in power unless there is a very large effect size.
- Would make sense to identify these patients for future cohorts * Consider using existing model (full dataset with continuous outcome) and create plots of marginal predicted probability * Top 10% are fixed, so may match to bottom 10% (note that bootstrap will resample zero over and over).
6 Feb 12
Mei Liu, DBMI, Staff
- Study on detection of adverse drug effect signalling
- Want to see which drugs or drug combinations have the most frequency
- Asked about how to use the "multi-item Gamma Poisson Shrinker (MGPS)" method by FDA on their lab data
- Suggested work with either Jonathan or Cindy through collaboration, or apply a VICTR voucher
30 Jan 12
Angel Sherrill and Ashley Pasquariello, IMPH
- Post menopausal women (median age 50+) without breast cancer or with breast cancer and initiating therapy -- paper survey. Women are enrolled via promotional material (like cohort study) with inclusion criteria.
- Internal Validity
- External Validity
- QoL and pain for women with and without breast cancer.
- Okay if they transition to online survey administration versus paper form administration?
- Should be fine as long as all respondents are able to take survey one way or another (reduce selection bias).
- Could include a covariate for paper vs. electronic entry in regression modeling.
- Heidi Chen provides support for IMPH
- Small study on the internet usage of this population -- binary logistic regression
- outcome: email address or opt-in
- covariates: cancer status, occupation, demographics
- suggest lit review for this specific aim and cohort
23 Jan 12
Carl Frankel, Psychology
- Heart rate variability - outcome measured 4 times. Interested in kids who stutter (subject to change over 2 year period).
- Potential time-varying confounding are height, weight, BMI. OK to use these? Yes. Could adjust for baseline + follow-up.
- How would you use these? Include in mixed model like other repeated measure data.
- May need non-linear terms in assumptions of linearity with outcome do not hold.
- N=120 with 60 stutterers and 60 non-stutterers with 4 time points.
- Suggestion for outcome (and repeated covariates): Instead of normalized change score, try using follow up as outcome and adjusting for baseline in model.
16 Jan 12
Aysu Erdemir, Erdem Erdemir, Brian Lawson, Psychology/EECE/MECE
- Prosthesis for amputees
- Stride measurement, fraction of stride instead of time
- 1 amputee vs. several healthy subjects
- Seeking a claim that are close to biomechanical norm for healthy gait
- Interested in characteristics of the device
- Important to word the conclusion correctly, e.g. "For this subject with this training ...."
- For the mean profile of the 10 control subjects (20 strides each) could improve slightly by displaying the 0.95 simultaneous confidence band for the population mean profile
- Superimpose the amputee profile and invite the reader to make a comparison without saying to
- Need to include a comment about how the amputee was chosen
- What about comparing, in the amputee, the active vs. passive leg?
- Potentially useful, but no inference is possible
- Add a spaghetti plot of all raw data, with amputee superimposed
Laurel Lunn, Peabody Human & Organizational Development
- Child mental/behavioral health services in Hawaii
- Travel to therapy, school's ability to care have an impact
- Length of stay in out of home treatment and ability of "good" schools to avoid the need for out of home treatment
- Rurality, income are of interest
- Several outcome variables, LOS in out-of-home setting is of primary interest
- What are community-level characteristics that impact this
- To get into the sample a chilld must have had at least one out-of-home treatment
- School unwilling to share info about in-school care
- Incomplete data on symptom severity scores
- To be able to use imputation need to assume that missingness is unrelated to child's condition or therapy choices
- Problem of collinearities among community characteristics
- May consider clustering of characteristics, combine those that are inseparable (using e.g. Spearman rho rank correlation)
- 42 school districts; use a stat method that handles varying cluster sizes
- Can interpret first principal components by seeing what it correlates with from among the constituent variables
- Warren Lambert would be good to talk to about multilevel modeling
Raafia Muhammad, Cardiovascular Medicine - see Tuesday clinic
9 Jan 12
Evan Brittain, Sandeep Goyal, Cardiovascular Medicine
- Mitral valve replacement in severe heart failure patients
- Clinical data, echo, preop data on everyone, postop on a subset
- 66 patients,
- Risk factors include LVEF, renal function, RV function
- Composite of death, transplant, left ventricular assist device placement (21 patients with at least one of these events); median f/u 17m
- Some deaths were found out using NDI; can't use deaths that occurred before a qualification time
- Binary outcome variables have minimum statistical information, so it is difficult to do more than estimate the overall incidence; breaking down by risk factors reduces denominators
- 40 have pre- and post-op LVEF; 36 have dimensions; same for LV mass
- May be more likely to get post-op echo if patient is sicker
- Suggestions:
- longitudinal descriptive stats
- calibration curve for predicted risk from models in the literature
- ordinal response multiple regression analysis (proportional odds model); increases effective sample size to allow for correlation analysis with baseline risk factors
- Look into how echos were read or make sure measurements were objective (e.g., computer derived)
Sarah Colona, Hematology/Oncology
- Triple negative breast ca < 1cm
- Tumor registry from 1980-2010; found n=60, mostly from 2000-2010
- Compare to other women with same size tumors but HER2+ or ER+
- Y=time to recurrence (may have around 10 events)
- A good way to get more information is to relax the tumor size cutoff and to use a database with several dozens of recurrences to estimate the relationship between tumor size and recurrence
- A problem is that tumor size helps drive the decision to treat with chemo; may want to analyze chemo and non-chemo separately
2 Jan 12
Vanessa Briscoe, Cardiovascular Medicine
- Submission to ADA with community partners (Alpha Kappa Alpha) Jan 17
- Health screening, education module dev by ADA
- Inform AA women re: CV, diabetes, obesity risk factors
- Deliver a program to teach how to modify lifestyle behavior/risk problems
- 4 groups: SoC feedback, Enhanced feedback, SoC and Program, Enhanced feedback+Program
- Enhanced feedback=more printed info; Program=ADA Choose to Live pgm
- Cluster randomized trial; 15 possible chapters to randomize; will need to rely on good luck to balance on baseline characteristics
- Think of as a 2x2 factorial design (enhanced feedback vs. not; program vs. no program)
- Return in 3m; measure cholesterol, weight, height, BP, waist circ, BMI, glucose
- Repeat at 6m
- Need to worry greatly about dropout rate because dropouts are not at random
- Need to discuss past track record in similar studies/people, incentives to stick with the program
- Sometimes it works to consider the outcome variable at the worst level if could not be measured because of dropout
- Outcome variables: (1) blood glucose, (2) LDL cholesterol, (3) BMI, + more secondary outcomes
- Don't need multiplicity adjustment if have a strong priority ordering for the order in which outcomes will be tested and reported
- Need a standard deviation of glucose or log glucose from a compatible reference sample, possibly age,race,sex-matched
- Analysis plan: 2-way analysis of covariance adjusting for baseline glucose; will adjust for intra-cluster correlation using the cluster sandwich covariance estimator
- Test of enhanced feedback: contrast groups 2+4 vs 1+3; for program contrast 3+4 vs. 1+2
- Test of synergism (interaction; effect modification): interaction between enhanced feedback and program
- For power analysis need difference in glucose you would not like to miss, along with standard deviation of person-to-person glucose measurements
- Sample size justification/power calculation will be done using alpha=0.05, power=0.9, equal sample size in 4 groups
- Alternative: use the Framingham risk score as the outcome variable (the linear score version of it)
- Or find a diabetes risk score to use
- Could make a risk score the primary outcome to be tested, but still look at individual outcomes/risk factors
12 Dec 11
Keisha Mitchell and Michael Rosen, Pediatric GI
- Design 'medical decision making' survey to understand reasons/motivations for parental decisions on treatment regimens.
- Interested in what treatment attributes affects decisions along with demographics and other parent characteristics.
- Simulate real world decisions by presenting options for treatment to parents of children with disease.
- 5 treatments with different route of administration, effectiveness, child growth, and risk.
- Allow for choice of treatment A and B (all pairs of 5 treatments).
- Some question as how to present effectiveness/risk (% versus ratio... 2 in 10,000, etc.).
- If risk is the measure of interest, how to assign risk to each medicine and quantify parental decision based on risk.
- Some relationship to time trade-off utility literature, possible relation to medical decision making in cancer (biopsy or not). * VICTR studio to find Vanderbilt personnel with medical decision making background.
Abby Brown, BRET/CTSI [returned 19Dec11 with data which we started analyzing]
- Do GRE scores predict success in graduate school? 1148 students in IGP at Vanderbilt since 1992.
- Data includes undergrad GPA, GRE scores, class rank (1st year), completion (1st year), passed qual exam, graduated with PhD. Since 2007, grad student exit survey (>97% complete): sci publications & presentations, fellowship. Mentor evaluation of graduate.
- Analysis considerations
- missing data -- 1200 matriculate, ~100 withdrawn, some have indeterminate status. * restrict to students who should be done (known grad or dropout) -- model odds of graduating with PhD (logistic regression) * important not to include dropouts when we are not sure of success of remaining cohort. * could model time to failure (dropout) to investigate early failure and censor those with unknown status -- allows for use of all data. * could model time to success (graduate) to investigate success and censor those with unknown/failure status -- also allows for use of all data.
- consider time trend (interaction of time and GRE score), pregnancy
- look at ETS models/research for GRE scores
- other measures of success (among graduates): post-doc, # pubs (impact factor).
- log-linear or Poison regression with # pubs as outcome
- Check out 'spreadsheet from heaven'
Jill Obremskey, Peds/ED
- Evaluation of guidelines for asthma outpatient and clinical outcome measures (~750 visits in 2009 ).
- Outcome is return to ED following visit in fast track for asthma/wheezing. Is rate different before and after roll-out of guidelines?
- Individual who is poorly controlled comes in 4-6 times per year -- guidelines aimed to decrease return visits.
- Question on how to collect data -- retrospective review
- Outcome is return to ED following visit in fast track for asthma/wheezing. Is rate different before and after roll-out of guidelines?
- Ben Saville, Wenli Wang, and Kelly Lu serve as biostatistician collaborators with Pediatrics.
28 Nov 11
Megan Strother, Radiology
- A Quality Improvement Initiative to reduce unnecessary dual-phase head CT exams (VR2509)
- multiple research endpoints; before and after intervention
- $5000 estimated for biostatistical support
21 Nov 11
Bill Wester, Infectious Diseases, Dept. of Medicine
- Long-term complications in nephropathy in HIV
- African-Americans with high levels of protein excretion; spot morning urine tests
- Prevalence of urine albumin:creatinine ratio > 300
- How has the ratio been validated for adequately capturing the prognostic information in both the numerator and denominator
- Creatinine has a non-monotonic relationship with mortality
- Enroll 24 of the patients in an RCT; 12 vs 12; 12w of drug (angiotensin receptor blocker)
- Baseline measurement of ACR, outcome is ACR also (16w)
- A secondary analysis could ask whether constituent variables predict final ACR better than baseline ACR does
- Take logs of baseline and final
- Could increase power slightly and make better use of partial information by using a quadratic time-response mean profile (or linear if OK to assume this); longitudinal model - generalized least squares or mixed effects model especially if > 1 dropout
- Contrast of interest: difference in mean log ACR at 16w projected from the linear or quadratic model with time x treatment interaction in the model
- Consider getting ACR at 4w and 12w also
- Is there a plasma biomarker?
- Interested in screening earlier
- VICTR biostat voucher request estimate $3000 (roughly 30 hours); home division would need to pre-approve paying for $500
Lou Iorizzo, Dermatology, Medicine
14 Nov 11
Lou Iorizzo, Division of Dermatology, Dept. of Medicine
- Retrospective study: superficial melanoma
- frozen sections to read pathology
- Central section sent to eval true depth of lesion using permanent section staining
- 2004 - Sep 2011
- How many upstaged to invasive melanoma when originally superficial melanoma
- Assuming sample is representative, still need to compute confidence interval
- Recommended method: Wilson 2-sided 0.95 confidence interval for the true probability
- Can use a t-test or better: Wilcoxon-Mann-Whitney 2-sample rank-sum test to compare age for those upgraded vs. not upgraded
- For location: chi-square test for a 2x2 table
- Power is limited by 14; confidence limits for differences will keep limited sample size in perspective
Ashley Karpinos; Med-Peds/VA Quality Scholars; MPH student
- Cross-sectional study to determine prevalence of hypertension in collegiate male athletes esp. football vs. other
- 1600 athletes at VU from 2003 to present; pre-participation physical by nurse
- Population comparisons will be problematic
- BP over 4 years; possible time to hypertension analysis (problem: assumes biologic discontinuity at threshold)
- Can model BP as continuous and still estimate the probability that BP > x; will be a function of covariate settings
- Candidate models: mixed effects model or generalized least squares; also summary measure approach (response functions - response feature analysis)
- Rough estimate: 20-35 hours of biostatistician time (about $3500)
Candace McNaughton, Emergency Department
- Interested in writing a paper
- Does length of boarding (captured accurately) related to later preventable pressure ulcer
- 2008-2011 data available
- Adjust for age, sex, Braden score (aubulatory, skin moisture, diabetes, etc.), ICU admission, hypotension, use of pressors, PVD, diabetes
- Same patient can have repeat visits (use # previous visits as covariate?; account for non-independence)
- Transformation of boarding duration to achieve adequate model fit, not to account for non-normality of covariate
- Cubic splines are a good way to model nonlinear effects
- Need to think hard about which interactions are likely to be important, using clinical knowledge
- Predict boarding time from all baseline covariates to discover if boarding time is a stand-in for other factors (e.g., comorbidities)
- May want to repeat outcome analysis removing variables highly correlated with boarding time to get a handle on the unique contribution of boarding time combined with things related to boarding time
7 Nov 11
John Reese and Jana Reece, Finance
- Data visualization for dashboard -- OR utilization -- (# minutes in OR)/(# minutes OR time available) for four timepoints.
- Rather than show mean % OR time, desire some level of uncertainty, SD is huge for 4 timepoints.
- Suggest showing the raw data (e.g. strip chart) by day of week. Other options: violin or bee swarm plot.
- Consider a graphic with calendar week on x-axes, and one line per weekday (spaghetti plot).
- Box plot is a good standard plot, could overlay raw data.
Gregoire Le Bras, Surgical Oncology
- Data visualization -- 3 cell lines, treatment A or B (6 conditions) -- 2 or 4 replicates per cell line.
- 1 replicate per slide with tx A and B on the same slide.
- We want to compare treatment while controlling for effect of slide. This is a repeated measure problem.
- Consider coloring points by slide #. bwplot from lattice gives boxplots.
- Data analysis
- For comparisons.... consider a linear mixed effect model - fixed effect is cell line, treatment, interaction and random effect is slide.
17 Oct 11
John Cleator, Nancy Colowick, Pharmacology
- Platelet aggregation
- Non-type II Diabetic patients vs. type II DM
- Good sample size for African Americans; those with DM don't seem to be resistent, i.e., act as if they don't have DM
- Previous multivariable analysis done by Dana Blakemore indicated the difference not explained by other variables such as age, sex, BMI; have not looked at med usage
- There are only about 15 AAs without DM (effective or limiting sample size)
- There's about a dozen meds to account for
- Comparisons of most interest
- % inhibition with 2-MeSAMP (or some transformation) = DM + age + sex + race + BMI + meds (try to limit to 6)
- Subset: low thrombin
- Main interest: DM (regression coefficient = difference in mean % inhibition at any fixed combination of age, sex, race, ...)
- Repeat for high thrombin (each subject had multiple aliquots treated after blood drawing)
- Repeat for low, high PAR1-AP
- Repeat for low, high PAR4-AP
- All of these involve 2-MeSAMP
- % inhibition with 2-MeSAMP (or some transformation) = DM + age + sex + race + BMI + meds (try to limit to 6)
- Diabetes column: if MS (metabolic syndrome), ignore
- Assume blank in any column (other than continuous numeric variables) represents No
- Ignore BAPTA
- Use only FLOW worksheet
- Do first for fold change (Value 1, Value 2, Value 3)
- Then repeat for % inhibition
- untreated = antagonist none, concentration low (single number per subject per compound)
- % inhibition = 100*(untreated - treated)/untreated = 100*(1 - treated/untreated) -> analyze log(treated/untreated)
- Long-term need to consider untreated as another observation, estimate the effect of being treated
03 Oct 11
Ruki Odiete (medicine)
- the same research question from last time
- Poisson regression model of readmission rates on MAP (continuous), controlling for race, gender and other confounding factors
19 Sep 11
Ruki Odiete (medicine)
- Baseline blood pressure measured on the first visit to hospital during 2006.01.01-2008.12.31
- Research question: the association between # admissions to hospital of heart disease patients and their baseline blood pressure
- Event count ranges from 0 to 10 over the whole study period
- A more appropriate outcome is the rate, number of events divided by the number of days from baseline to the end of study for each patient.
- Patients who died or moved away from the area during the study period
12 Sep 11
Baqiyy ah Conway (Epidemiology)
- Diabetes before age 30 (self report) in Southern Community Cohort age 40-79
- Excluded subjects diagnosed after age 30
- Avg age = 50; avg f/u 4 y
- Missing people who died before age 30 or who were diagnosed between age 30 and 40
- Reviewer comments: adjust for left truncation in analysis; f/u by itself is shorter than duration of diabetes at baseline
- Can estimate, with t = time since study entry, S(t | entered study, did not die before age 40, did not have diabetes onset between age 30 and 40, covariates measured at t=0, time since onset of diabetes if diabetes developed between age 40 and study enrollment, perhaps using zero if not developed diabetes)
- So not clear why left truncation needs to be used at all
- When used time from study entry and controlled for age at enrollment, got similar hazard ratio as using age at entry and age at death as the interval
29 Aug 11
Joe Fanning, David Schenck, Lee Parmley, Anne Miller, Larry Churchill (Medicine, Anesthesiology, Biomedical Ethics)
- Consultants: Frank Harrell, Matt Shotwell, Cindy Chen, Svetlana Eden
- Needs assessment
- Setting Expectations Early in the ICU
- Understanding communication practices; try communication intervention
- Main target: family satisfaction; studio presented the pilot study (discussed weakness of history control design)
- Outcomes: family satisfaction, time to decision, LOS
- Can a controlled trial without randomization be useful?
- 3 ICUs
- SEE meeting: attending physician (4/units) + family
- Daily survey short; family satisfaction survey 24 items
ICU # Time 1 Time 2 1 Historical Satisfaction survey 2 Historical Daily survey + sat. survey 3 Historical SEE Meeting + daily + survey
- Expect a good deal of within-physician learning
- Some physicians can attend at more than one unit
- One family may be dealing with more than one attending
- Would a crossover design work? Hard to withdraw something that is perceived to be effective.
- What about a randomized entry time design?
- Ultimately need to randomize >= 20 ICUs at multiple hospitals
- May want to do a pure feasibility study
- May only need one unit at VUMC for feasibility study; would be disqualified from future cluster randomized study
2011 August 22
Warren Dunn, Suzet Galindo-Martinez, Emily Reinke, Sports Medicine
- prospective longitudinal cohort study enrolled at time of surgery.
- variety of measurements are taken at baseline and then 2 and 6 year.
- Want to discuss including time varying covariates in longitudinal model.
- Some variables that will change over time and influence the outcomes are: marx activity level, bmi, subsequent surgeries,
- Outcomes: sf36 general health, koos and ikdc which are knee related.
- We think that the outcome could influence activity level, which could then influence the next outcome measurement.
- How strong of a predictor is the sf36 of marx. Can measure this using a model, like a propensity model.
- Transition model: do we want to use a time lagged model (use t2 sf36 to predict t6 sf36).
- Main question we want the models to answer is: what are the predictors of these outcome metrics.
- Since the goal is prognostic, we don't need to worry as much about things that also
- Interpretation of activity level is different at baseline and 2 years, since 2 years is after a major surgery intervention.
- Another way to model this is to only model the 6 year outcome as a function of the t2 and baseline data.
- Mediation analysis: predict t6 using t2 and t0, and then using only t0.
- 15-20 % had additional knee surgery.
- A separate question could be whether sf36 predicts requiring additional knee surgery.
- Could also add an interaction of all terms with time.
Paula Williams, Stacy Killen, Pediatric Cardiology
- Fatal tachy arrhythmia
- Why do some babies present with tachyarrythmia after birth or later, rather than in utero.
- Retropective chart review
- Want to identify factors that explain different in time of presentation
- If the mother isn't getting pre-natal care, they may not have the opportunity to present before birth.
- Could use everyone who gets referred to their clinic, which will be a well-defined population.
- Recommended they contact Ben Saville
15 Aug 2011
Matt Morris, Psychology
- Research question: why do some women exposed to inter-personal violence develop PTSD (Post-traumatic-stress disorder) and other don't.
- Cohort: 50 subjects, 18-25 year old, female, African-American, no medications (except oral contraceptives)
- Hypothesis: increase (compared to the first measurement) of PTSD severity is associated with decrease in daily cortisol output (compared to the first measurement).
- Primary outcome, PTSD score with range of 0-136 (0 - no trauma, 136 - severe trauma), measured at 1 month after the index event (AIE), 2 months AIE, 4 months AIE, and 6 months AIE
- Main covariate: level of cortisol at 1 month AIE, 2 months AIE, 4 months AIE, and 6 months AIE
- Problems:
- no control group
- no baseline of cortisol (cortisol level before the event)
- Recommended:
- include control group (think of inclusion criteria - think of a definition of "relatively trauma free")
- to balance the budget, it might be better to reduce number of time points
- twenty hours for developing study design
8 Aug 2011
Salyka Sengsayadeth, Hematology/Oncology Dept. of Medicine
- VICTR submission
- Stem cell transplant - impact of CLTA4 SNP on outcome (survival)
- Expand prelim data to larger cohort; f/u of 3y
- Goal is to personalize treatment related to transplant
- Pre-review comments to discuss
- Test for Hardy-Weinberg equilibrium - what alpha level to use (P > 0.001?) ; could decrease to 0.005
- General issue: do we operate under an assumption that is favorable to us or unfavorable?
- Effect size to detect hazard ratio=1.5 (assume using a Cox proportional hazards model); power 0.8
- Power = 0.9 n=1467 (actual n=1172); power=.8 n=1124
- For future would also be good to state in terms of expected margin of error (fold change from 0.95 confidence limit for hazard ratio)
- Standard error of log hazard ratio is approximately 2/square root of number of events
- Clinical variables to adjust for: age sex city performance status, risk status at transplant, conditioning regimen, ablative vs not, donor age, sex, hla, cmv status, source of stem cells, cell dose, GVHD prophylaxis, acute/chronic GVHD, T-cell depletion involved
- Open to successions regarding the development of a sequential design; better here may be a case-cohort design; this would save money
1 Aug 2011
Teddi Walden, Elizabeth Will, Human Development - Peabody
- Studdering - 3, 4, 5 year old; risk of behavior problems
- Need to account for sex
- Behavior problem scores have a very heavy left tail; most children get a score of 0 or 1; basis: never, sometimes, often
- Proportional odds model may be ideal with respect to Y, but be careful about what is assumed for covariate effects
- Get cumulative distribution of Y by strata (sex x studder) and take logit transformation
- Curves should be almost parallel
- Alternatives: continuation ratio model (discrete proportional hazards model - assumes parallelism of log-log 1-cumulative distribution plots); probit; parametric (e.g., gamma, beta); Poisson
Eugenia McPeek Hinz - DBMI grad student
- Disease burden in outpatient populations
- Lee 4y mortality risk model developed on outpatients; has predictions from 0.01 - 0.66
- How many people would need to take a new survey to allow computation of the Lee mortality index so that an adequate comparison with the EMR-derived approximate index can be made?
- Target could be the precision of the average absolute discrepancy between the two methods
- One approach is to do a pilot study of 35 patients to estimate the S.D. of the absolute differences, in order to compute the final sample size
- An upper bound on the sample size may be obtained now, using S.D. of the approximate indexes
- Later do a Bland-Altman plot to show that the differences do not vary systematically with their average or with some covariate
- Also for later, an alternative approach is to predict the Lee index from a combination of all available items and hope for an R-squared > 0.85
- Likely to require > 500 patients having the Lee administered
25 July 2011
Michael Bowen, Henry Ooi: RCT HF Centralized Care Support and Improved Primary Care
- Pharmacist assists with medication titration; phone support
- 3 remote primary care clinics, 3-5 providers each
- 6 Providers volunteered according to interest; 3 clinics
- Control providers/patients - same clinics
- 1y study
- Y = 9 HF quality measures (was wt measured; assess activity level; assess vol. overload; on ACE or AR blocker; achieve target dose; on beta blocker; met target dose; on evidence-based beta blocker; on coumadin if have Afib)
- Target: at least 20% improvement in at least 3 of 9 performance measures
- Proposed analysis considers each of the 9 separately; statistical evidence to be synthesized
- Data acquisition during scheduled primary care visits; chart review to get baseline measures
- End of study visit taken to be at date closest to study closure date
- Discussed longitudinal time trend analysis instead of study end analysis
- Watch out for unequal number of visits in intervention vs. control
- Control patients may not have intermediate visit data; need more information/feasibility of getting the data post facto
- If that can be solved, may want to consider computing the average per-visit number of targets met
- Pts can change providers (e.g., move from study to control provider) and sites
- n=130 x 2
- Need to adjust for severity of HF (e.g., LVEF), age, comorbidities, weight
- Biggest threats to validity: non-random selection of providers in the intervention group, unequal data collection between the two groups
Update 8Aug11
- Complete data on study entry and exit
- No intervening visit data for control group
- Cost to fetch this is prohibitive
- Major problem is that "last visit" could apply to a wide time span; target for end-of-study visit 1y but could be 1m; likely a "healthy person" bias
- Goals: report to funder (VA HF query group), paper in the quality literature
- Original plan used follow-up of at least 6m; hierarchical GEE negative binomial, control charts
- Suggestion to find a follow-up time point and define a window around that where an (actually occuring) visit within the window would be used for the determination
- Analyze Y=0-9 per patient using Wilcoxon test for example; report the mean number of criteria met in each of the 2 groups
- To adjust for baseline: consider proportional odds model (generalization of Wilcoxon test; handles huge number of ties very accurately)
- Most important baseline covariate: number of criteria met before the intervention started
- Find out which number of months since index time had the greatest number of end-of-study visits in both treatments combined (+/- 2 weeks for example)
- To adjust for baseline: consider proportional odds model (generalization of Wilcoxon test; handles huge number of ties very accurately)
Tolulope Falaiye, Pediatric Gastroenterology
- Signal transducer Stat6 - stat proteins active in inflammatory conditions
- Contrast ulcerative colitis vs. non UC IBD
- Will use flow cytometry to look at a whole family of stat proteins
- 4 groups (no IBD, UC, Crohn's colitis, Crohn's ileocolitis)
- n=20 per group targetted
- Same pathologists read all the samples and used a scale
- Also look at intensity levels using e.g. Kruskal-Wallis test
- Need to account for past treatment?
- Choice of area in intestine to biopsy is not protocolized
- How many biopsies to analyze per patient?
- Need difference not to miss, and standard deviation, then we can help with a sample size calculation
- Don't base the calculations on "differences in standard deviation units" except as a last resort
18 July 2011
Special Clinic: Capturing Smoking History
The following summary was provided by Pierre Massion The field remains wide open and yet with a rich history. I think there is both a need and a wish to pursue your idea of streamlining smoking history capture and identify best variables to reflect accurately the history. These will probably vary from disease to disease state. As it relates to lung cancer risk, we discussed some key variables and here are those I believe are most informative at this point:- smoking initiation age
- smoking cessation age (months since stopping if recent)
- intensity of smoking (number of pack per day)
- duration of smoking (years)
- smoking status (Never, former, current)
If there is a will for a pilot a study modeling these variables in the SCCS and maybe in the PLCO or NLST databases, I think this would be very valuable and I would be happy to contribute what I can.
Below, you will find some relevant literature.
- Variations in lung cancer risk among smokers. Bach PB, Kattan MW, Thornquist MD, Kris MG, Tate RC, Barnett MJ, Hsieh LJ, Begg CB. J Natl Cancer Inst. 2003 Mar 19;95(6):470-8. 12644540
- The LLP risk model: an individual risk prediction model for lung cancer. Cassidy A, Myles JP, van Tongeren M, Page RD, Liloglou T, Duffy SW, Field JK. Br J Cancer. 2008 Jan 29;98(2):270-6. Epub 2007 Dec 18. 18087271
- Smoking, smoking cessation, and lung cancer in the UK since 1950: combination of national statistics with two case-control studies. Peto R, Darby S, Deo H, Silcocks P, Whitley E, Doll R. BMJ. 2000 Aug 5;321(7257):323-9. 10926586
- A risk model for prediction of lung cancer. Spitz MR, Hong WK, Amos CI, Wu X, Schabath MB, Dong Q, Shete S, Etzel CJ. J Natl Cancer Inst. 2007 May 2;99(9):715-26. 17470739
- Validity of self-reported smoking status among participants in a lung cancer screening trial. Studts JL, Ghate SR, Gill JL, Studts CR, Barnes CN, LaJoie AS, Andrykowski MA, LaRocca RV. Cancer Epidemiol Biomarkers Prev. 2006 Oct;15(10):1825-8. 17035388
- Lung cancer risk prediction: prostate, lung, colorectal and ovarian cancer screening trial models and validation. Tammemagi CM, Pinsky PF, Caporaso NE, Kvale PA, Hocking WG, Church TR, Riley TL, Commins J, Oken MM, Berg CD, Prorok PC. J Natl Cancer Inst. 2011 Jul 6;103(13):1058-68. Epub 2011 May 23. 1606442
- IARC Monographs on the Evaluation of Carcinogenic Risks to Humans Volume 83 (2004) Tobacco Smoke and Involuntary Smoking. http://monographs.iarc.fr/ENG/Monographs/vol83/index.php
20 June 2011
Keisha Hardeman, Cancer biology
- Writing a proposal for a pilot study on head and neck squamous cell tumors. A surgeon is resecting tumors, and will later evaluate whether the patient responded or did not respond. We advised them to check with the surgeon to find out what criteria are used to make that determination.
- Could use logistic regression if there is not more information in the outcome.
- Could use the popower function in Hmisc package of R to determine power/sample size for proportional odds logistic regression if the outcome is ordinal. The models can be fit using lrm function in rms package.
Dr. Carrie Geisberg, Cardiology
- Prospective study on anthrocycline treatment for breast cancer. Exercise/activity level is measured at baseline and then four times during treatments.
- Want to look at association between the exercise and some biomarkers to help decide if it's necessary to continue to collect these activity data.
- Run linear regression with separate predictors for each exercise measurement. Fit two models: one with all linear terms, and one model including quadratic terms for each predictor. Choose one based on the AIC and stick with it.
- Can do redundancy analysis on the five exercise variables and also the five biomarkers.
- Use care when interpreting the results, given that this will be under powered. Focus on confidence intervals rather than point estimates and p values.
- Be sure to consider the scale of the exercise variables when interpreting the slope estimates.
- Lower limit of detection problem: Find out what percent have this issue.
6 June 2011
Bobby Bodenheimer, Erin McManus, Aysu Erdemir, Electrical Engineering/Computer Science and Psychology
- Virtual environment lab -- interested in how persons perceive throwing when trajectory is modified (e.g. gravity, wind, etc.).
- Maximum likelihood procedure to determine perceptual threshold.
- Threshold - perturbation level at which 75% or better of throws correctly identifies perturbation.
- Repeated measures -- 3 perturbations and 2 directions per participant repeated until convergence for 6 males and 6 females.
- Vertical velocity, horizontal velocity, gravity are perturbations.
- Repeated measures ANOVA with Greenhouse/Geiser correction was used for analysis.
- Concern that scales (unit of measurement) are different for gravity and wind perturbations.
- Consider using separate models for each perturbation type and separate graphical features.
- Consider using raw event data (binary) versus threshold (discarding event data); though with iterative data collection this is difficult (serial correlation).
- Use pairwise comparison within perturbation type for univariate comparison (t-test).
- Instead of repeated measures ANOVA, consider a mixed effect model (with random effect for subject and fixed effects for sex and direction of perturbation).
16 May 2011
Alexander Langerman, Otolaryngology
- Survey of surgeons (American Head and Neck Society) on tissue collection and repository.
- Content: importance (likert), consent, procument, processing/storage
- Collection: When identifying barriers to tissue repository, could do check all that apply or rank order?
- Response Rate: Hoping for high response because surveys are not common among this group. Consider targeting survey to smaller group with incentive or reminders.
2 May 2011
Le Bras Gregoire, Surgical Oncology
- Tissue microarray - punch biopsies
- CD44 vs. E-cad antibody staining
- 2x2 table, 166 patients
- Use of continuous proportion of cell positive would greatly increase the power
- An even greater increase may be had by analyzing grades of all individual cells
- But individual cell data may not be available
- Make scatterplot of % cells positive by one method vs. % positive by the other method
- Can estimate the shape of the trend of one vs. another using a nonparametric smoother (nonparametric regression)
- Quantify association using Spearman's rho
- Could repeat for other cutoffs of grades
- Can do similar analyses for localization
Carl Frankel, Psychology
- Mixed effects model
- Interest in comparing standard errors of parameter estimates
- F-ratio test is highly dependent on normality; also estimates may be correlated
- Try to formulate hypothesis in terms of raw input data, or watch out for hidden collinearity inflating the standard error of one parameter estimate
- Is a normal model justified? How about using a mixed effects ordinal logistic model?
25 April 2011
Emily Reinke and Suzet Galindo Martinez, Sports Medicine
- Has a cohort of ~170 patients who have undergone acl reconstruction.
- Wants to model the association between clinical laxity measurements and patient-reported stability outcomes.
- Can try ordinary regression for the two continuous stability measures, looking at the residuals and transforming if necessary.
- For quantifying the extent to which the laxity predicts the stability, emphasize the adjusted R-squared and the mean absolute error in predicting the stability
- For the two patient multiple-choice questions, can use Somer's Dxy as a correlation measure.
- Include 2 or three measures of laxity in the model.
- Can include all interactions (with bmi, age, gender and activity level), and then do chunk tests and exclude the non-important interactions.
- Could also possibly use multiple imputation to impute the "guarded" pivot shift measurements using the info from the other two laxity measured
Amy Dickey, Cardiology Department
- Wants to account for exercise (ordinal 1-4) before starting a chemotherapy in a model predicting cardio toxicity
- It would be good to avoid looking at the data as a percent change
- It would be good to not dichotomise the outcome
- Adjust for baseline echo
- Adjust for the exercise in the model
- Give scatterplot of baseline v. post outcome (can use different color for different types of patients (male/female))
- Possibly truncate ejection fraction at 60(?)
- Consider previous treatments
ejection fraction (post) = ejection fraction (pre) + exercised before + error
Michael Poku, med student
- Has repeated measures on 130 patients
- Wants to look at effect of a medication treatment on blood pressure in hypertensive patients
- Patients are measured at different times
- There is not real baseline measurement
- The dose of the medication changes at day 21
- Does patient monitoring affect patient outcomes? Affect treatment adherance?
- Need a control group.
- Consider regression to the mean, specifically, if you choose the patients who have extreme blood pressure, they're definitely going to regress to the mean.
- Consider designing a prospective study with a control group and a good baseline measurement.
11 April 2011
Swati Rane, Radiology VUIIS
- Healthy (n=10) vs. schizophrenic (n=8)
- 2 measurement methods: steady state values vs. temporal - using blood flow to estimate blood volume
- Cerebral blood volume - cbv
- Used Lilliefor's test of normality
- Assumed that this test had a power of 1.0
- Need to choose a measurement method in an unbiased fashion that is not optimizing the disease difference
- E.g., choose the method that minimizes the average (over disease groups) of the within disease group mean absolute difference
- This assumes that both measures are absolute in a certain sense; are seeking a calibration factor
- May have to do 2 separate analyses
- mean abs(T1 - T2) for normals then for schiz. (looking at discrepancy between T1 and T2, separately by disease)
- Wilcoxon-Mann-Whitney 2-sample rank test for T1 (schiz. vs. normal) then for T2; multiply p-values by 2 (Bonferroni's inequality)
- Could test for differences (schiz. vs normal) in rank correlations between T1 and T2
- No matter what analysis is done, we assume that relative measures T2 mean the same thing for one patient as for another
- Another approach is to see how both measurements jointly relate to disease status
- Binary logistic model to predict the probability of schizophrenic (Y=1) as a function of a combination of T1 and T2
- Prob(Y = 1 | T1, T2) = logistic function 1/[1 + exp(-x)] of b0 + b1*T1 + b2*T2 (n=18)
- H0: b1 = b2 = 0 (likelihood ratio chi-square test with 2 degrees of freedom)
- H0: b1=0, H0: b2=0 (each test adjusted for the other): e.g., b1 is "signif." and b2 is "not signif." one would conclude that T1 has a signal for diagnosing schiz. and T2 is unnecessary, given T1 (T2 provides no useful extra information over T1)
- Would have FAR more power if there is a degree of severity of schizophrenia
- One of the 18 subject is schizo-affective. But s/he was not diagnosed using T1 in this study
- Note: Other studies have failed to find a correlation between T1 and T2
- Because of measurement errors it may be necessary to make multiple measurements per patient per method
4 April 2011
No clients
* Discussed survival and case-control analysis.28 Mar 2011
No clients
* Discussed HTML5.14 Mar 2011
Amanda Salanitro, Medicine
* 3 timepoints for prescription -- match pharmacist with physician. 60% had no discrepancies. Count of discrepancies and count of severe discrepancies. * predictors: number of medications that patient comes in on, pre-existing list of medications, understanding/adherence. * modelling count data with lots of zeroes -- need to use zero-inflated methods?7 Mar 2011
Heidi Hamm and Nancy Colowick, Pharmacology
- Platelet function in normals and type II diabetics
- Total of 130 subjects; AAs and Caucasians
- Activation of platelet integrin - PAC1 antibody used to measure it using flow
- Ability of platelets p-selectin (also a flow)
- Thrombin is a major platelet activator; par1 and par4 receptors
- Diabetics are resistent to various compounds such as Clopidogrel rel. to P2Y12 receptor
- AAs seem not to be as resistant
- Aim 3: Pts with CAD coming for stents, looking at the subset that is diabetic: p3a3
- Aim 4: Diabetic volunteers: p3a4
- Response Y = Pre-bivalirudin, P-selectin & pap1 (GPIIbIIIa)
- Analyses separately by condition (36 aim 3, more aim 4). Start with prototype Thrombin none low
- In spreadsheet, Weight is really BMI
- Basal levels have already been normalized for using fold change
- Study metabolic syndrome will need to go back to charts to get data for classification
- Grant application due April 1; there is also a paper to submit
John Benitez, Medicine, Clin Pharm, Toxicology Section
- New tx of poisoning (overdoses) with calcium channel blocker meds (typically for hypertension) using fatty acids
- How to define baseline pre-overdose blood pressure for a subject?
- One infusion, look at BP response; single-arm study
- Could consider a factorial design if want to entertain other drug delivery approaches
- Rare situation in most sites; how to keep study personnel trained?
- Not all presenting subjects will have ca channel blocker overdose but will have similar symptoms
- First will do a safety study on normal volunteers
- 50% mortality
- What is endpoint and how to code it when death occurs?
- Current thinking is BP at 20 min.
- could consider time until BP > lower limit of normal (time = infinity if died)
28 Feb 2011
Elizabeth Moore, Nursing
- Planning a Cochrane neonatal review for intervention: skin-to-skin contact of NICU child with mother. Outcomes are breast feeding, mother-infant attachment, and adverse events.
- Some suggestions from protocol review:
- Using fixed or random effects in analysis due to diversity in control and skin-to-skin conditions. * May try to account for dose-response effect (dose being the frequency and amount of time there was skin-to-skin contact). * May plan to subset analysis for different control conditions. * Typically if there are >3 studies, random effects models are used for meta-analysis. * Avoid sensitivity analyses unless there is a clear decision rule for differences in models, better to use robust methods. * Just used odds ratios, not both odds and risk ratios.
- In addition to individually randomized trials, they suggest cluster randomized and crossover trials may be included * Will consider cluster RT if estimates of intervention are adjusted for baseline differences in patient population. * Crossover trials may have carryover effects, so only data from the first randomized time period would be included.
- Request VICTR funding to work with Chris Fonnesbeck
- Kathy Hartman and Melissa McPheeters work with many Cochrane reviews in Epidemiology.
Dan Kaizer, Cardiology
- Want to plot the impact of polymorphism on absolute risk. Consider x-axis with probability of afib as a function of all variables. Then include the polymorphism in the model and plot the probability of afib on the y-axis.
- Performed logistic regression with interaction between statin and polymorphism in SPSS. Difficult to contrast groups in SPSS. To get the OR and 95% CI of interaction effect, take antilog(Effect), antilog(Effect+-1.96*SE).
- How do you combine four regression estimates if you have four confidence intervals? Consider a weighted average of the odds-ratios.
Veronica Oates, TSU Family and Consumer Sciences
- Survey of 52 parents on parent/child interaction.
- 10 questions on parent-child interaction, interested in developing a scale to compare with other scales.
- Testing for validity and reliability of measuring a construct with survey questions is a study in itself. Consider searching for validated instrument when possible.
21 Feb 2011
Alicia Fadiel, Epidemiology
- Time to event analysis for polymorphisms associated with disease progression-free/overall survival in Shanghai breast cancer study. There are three studies: SPCS1, SPCS2, SPCSS.
- Time of diagnosis is start time. Surveillance for progression/death should be similar across studies.
- 8 polymorphisms of interest looking at research maturity over time (false positive biomarker findings) for different studies. Initial research is either less precise or biased towards 'winning' biomarkers.
- For Kaplan-Meier plots, try confidence band for difference in survival curves from SPCS1 to SPCS2. Try an interval chart (e.g., dot plot or Forrest plot) to show hazard ratios and confidence intervals by Stages 1/2.
- Consider including stage in the Cox PH models and test for interaction between genotype*stage. IF significant interaction, then "estimated effects of a genotype are in disagreement with each other by study".
Merida Grant, Psychology
- Interested in learning more about mixed effects models for analyzing repeated measures in stimulus experiments.
- A nice summary graphic for longitudinal data is the 'spaghetti plot' with time on the x-axis and response on the y-axis -- each subject has one line. Sometimes a LOWESS (locally weighted smoother) curve is fit to summarize the trend.
Karen Rufus, OTTED
- Karen is preparing a PhD dissertation proposal and would like feedback on methods. She plans to survey 15 directors at 15 weight loss centers to examine predictors of success/adherence. Suggest collecting objective information in addition to the opinions of directors. 15 centers may not be sufficient to detect differences, though patient level data may be recovered. Consider polling more centers, but not at the cost of a poor response rate. Next step would be to prepare a data analysis plan.
31 Jan 2011
Evan Brittain, Cardiology
- Interested in the agreement of two software users in MRI measurement. Try estimating the pairwise difference and calculating the confidence interval to determine difference among users. This method does not give consideration for repeated measures.
- To compare users, a linear mixed effects model will account for variability within raters and repeated measures per patient.
Quinn Wells, Cardiology
- Interested in modeling the effect of two continuous variables (and their interaction) on the occurrence of a heart related event (binary).
- Rather than cutting the continuous variable to tertiles, try using logistic regression with an interaction term.
Logistic Regression Model
lrm(formula = form, data = dat)
Frequencies of Responses
0 1
18 11
Obs Max Deriv Model L.R. d.f. P C Dxy
29 0.6 4.81 3 0.1862 0.629 0.258
Gamma Tau-a R2 Brier
0.259 0.126 0.208 0.204
Coef S.E. Wald Z P
Intercept 1.3057699 1.669843 0.78 0.4342
PDGFABBB_ng_mL -0.0859901 0.069629 -1.23 0.2168
VEGF_pg_mL -0.0112985 0.009698 -1.16 0.2440
PDGFABBB_ng_mL * VEGF_pg_mL 0.0005501 0.000435 1.26 0.2060
Effects Response : Collat
Factor Low High Diff. Effect S.E. Lower 0.95 Upper 0.95
PDGFABBB_ng_mL 18.480 38.284 19.804 -0.33 0.70 -1.69 1.04
Odds Ratio 18.480 38.284 19.804 0.72 NA 0.18 2.83
VEGF_pg_mL 80.644 154.370 73.726 0.18 0.35 -0.50 0.86
Odds Ratio 80.644 154.370 73.726 1.20 NA 0.61 2.35
Linear Regression Model
ols(formula = EF ~ PDGFABBB_ng_mL * VEGF_pg_mL, data = dat)
n Model L.R. d.f. R2 Sigma
29 1.203 3 0.04063 13.54
Residuals:
Min 1Q Median 3Q Max
-20.293 -9.316 -1.266 7.484 32.356
Coefficients:
Value Std. Error t Pr(>|t|)
Intercept 27.7357711 7.1874346 3.8589 0.0007112
PDGFABBB_ng_mL 0.1965671 0.2076831 0.9465 0.3529650
VEGF_pg_mL 0.0065939 0.0319017 0.2067 0.8379232
PDGFABBB_ng_mL * VEGF_pg_mL -0.0002420 0.0008774 -0.2759 0.7849180
Residual standard error: 13.54 on 25 degrees of freedom
Adjusted R-Squared: -0.07449


17 Jan 2011
Beth Shinn and Andrew Greer, Peabody HOD
- Want to develop a risk model related to a family entering a shelter (1000 events)
- Time zero = apply for services
- Issue with survival analysis in the presence of missing data (about 30%)
- Used ICE in Stata to do multiple imputation
- Have been deleting variables that are missing > 0.5 of the time
- R^2 in predicting an often missing variable is small
- 35 candidate variables; did a step-down variable selection down to 14 predictors (not recommended)
- Used more than 35 in the multiple imputation; can look at relationship between other variables and the missingness of a target variable to see if any imputers have been omitted
- Might consider some data reduction techniques (variable clustering, principal components, redundancy analysis, etc.)
- Remove some predictors or collapse into cluster scores
- Had difficulty in Stata in plotting the estimated baseline survival curve
- Probably need to estimate baseline survival separately for each imputation (i.e., each filled-in dataset)
- See how they vary over 10 imputations
- The average baseline survival curve (say at a grid of 200 equally-spaced follow-up times) is probably a valid estimate
- Use step-function interpolation to estimate S(t) at the chosen grid over t
- No need for this complication if there are no missing follow-up times/event indicators (all filled-in datasets will have the same unique event times)
- See if Stata has a function for getting the i'th filled-in dataset out of 10; run this 10 times
Kim Petrie - BRET
- Survey design question relating to career development
- PhD students entering in 2005; looking at career interests as leave graduate school and how these correlated with original interests
- Ordinal responses on a number of questions
Uche Sampson, Cardiovascular Medicine
- Evolution and size of mice aneurysms by dose of angiotensin infusion
- Benefits of smooth modeling of longitudinal data vs. separate time-point analysis
- Allow for treatment x time interaction
- Candidate models: regression spline for time effect (e.g., 3 or 4 parameters); generalized least squares or mixed effects model
Andrew Lagrange
- Normal electrical rhythm in brain slices; transient loss after injury
- Measured at specific times after injury
- Controls: 31 slices, 30 have normal rhythm
- Injury e.g. 3 with rhythm, 19 without
- 13-29 animals/group
- Multiplicity - comparing to the same control set at multiple times
- Easiest solution is to use Bonferroni's inequality: multiply individual P-values by the number of tests in total (here, 4)
- Ordinary Pearson-Cochran chi-square test is likely to yield more accurate P-values than Fisher's "exact" test
20 Dec 2010
Dan Kaiser, Cardiovascular Medicine
- Sample size need
- Existing database, genotyping to be done
- Postop atrial fibrillation; statins decrease this
- OR .76 for impact of statins in decreasing postop afib after adjusting
- 0.27 off statin, 0.21 on statin; no dosing available
- A polymorphism predicts statin response (CV events) - carrier of arginine
- Does it predict other impacts of statins?
- Afib treated as binary but ventricular response
- Pre-op Afib is adjusted for in logistic model (OR=4)
- Most pts getting statin because of undergoing CABG
- 0.57 on statins; everyone should have been. So there could be a significant selection bias.
- 0.59 of population have the risk allele
- Recommendation to interpret previous results using confidence intervals (NOT P-values)
- Risk allele present/absent, statins yes/no
- What is the power of the interaction test involving these two factors?
- Alternatively what is the margin of error for the log differential OR
- Variance of log of ratio of odds ratios is the sum of 4 terms of the form 1/[n * p * (1 - p)]
- n is the group size (there are 4 groups); p is the probability of postop Afib in that group
- A reasonable worst case to assume is that all 4 p = 0.15; ran for p=.1 to .3 and assumed BEST case of equal cell sizes
- Sample size appears to need to be > 2000 to achieve a multiplicative margin of error of no worse than 1.5
- This ignores covariate adjustment
- NOTE: If a continuous outcome variable were available the variance of the interaction effect would be a tiny fraction of the above
- It may be that it is infeasible to estimate relative differential genotype effect (interaction on OR scale) but it may be feasible to estimate the absolute differential effect (difference of risk differences); hard to do this in presence of adjustment variables
- Need perhaps a minimum of 950 subjects to have a margin of error that does not exceed 0.1 in estimating the difference of two risk differences, at the 0.95 confidence level
- One general conclusion: genotype everyone
6 Dec 2010
Liana Castel, HSR
- Longitudinal data analysis vs. time to event
Uma Gunasekaran, Endocrinology Fellow, Dept. of Medicine
- Gestational diabetes
- Demographics, look back a year before new tx began
- Look at diet, exercise, insulin, other meds
- HbA1c
- Historical controls for old diagnostics
- Rate of c-section, preeclampsia, difficult delivery, smaller babies
- Questionnaire for data not in EMR
- Descriptive analysis one risk factor at a time
- Can also cluster characteristics to see how they run together
- Use multivariable regression model if want to relate several variables to an outcome
- Need to pay special attention to differences in data definitions for new vs. historical cohorts
- But historical data are from the same clinic and physicians
- Talk to Kathy Hartmann about the Right from the Start study that has prospective cohort data
Michelle Shepard, medical student
- Individualized learning plans
- No literature on using these for medical students
- Pilot study on 4th years, Peds and Int. Med.
- Student self-assessments
- 2 learning objectives week 1
- Met with mentor, looked at meeting objectives
- At end of month, survey - how useful found the project, how satisfied
- Asked to rank usefulness of each component
- Estimated # weeks it took the student to meet each objective
- Examined correlation of outcomes with areas of weakness
- Likert scales, 1-5
- Might be OK to use means as descriptive summaries, but best to use nonparametric tests
- Same for 1-5 rankings and number of weeks to achieve objective (probably with asymmetry of data)
- May want to look into Rasch analysis
- Mario likely can do the analysis
29 November 2010
Anna Hemnes, Pulmonary Allergy & Critical Care Medicine; VICTR voucher applicant; assigned to Li Wang M.S.
- Pulmonary hypertension: arterial vs. venous
- No PH group similar to healthy controls
- Looking for differences in body mass, other medical conditions in the two groups
- Wanting to develop a clinical prediction model
- Is the model improved by incorporation to tidal CO2
- Right heart cath used as gold standard: LAP, PA diastolic - PA OP (occlusion/wedge pressure)
- Is it possible to put patients on a continuum? Perhaps using PA OP
- # candidate predictors = 1/15th of the number of events (lesser frequency of the two frequencies) if binary Y
- # candidate predictors = 1/15th total number of patients if Y is almost continuous or continuous
- Much greater effective sample size if outcomes are continuous (or ordinal with at least 5 well populated categories)
- Could also predict MPAP (mean pulmonary arterial pressure) or PVR (pulmonary vascular resistence)
- Predictors of mortality: RAP, CI, MPAP
- May be able to validate the model using resampling on the original dataset instead of waiting for new data
- There may be opportunities to validate the model in another institution
- Suggest 45 hours to request (20 hours free, home Division has to support paying for 1/2 of 25 hours)
Sharelle Armstrong, GI Medicine
- Depression in inflammatory bowel disease (IBD)
- Data already collected (n=157 with IBD)
- SIBD-Q score measures severity of IBD
- PHQ-9 scores (0-30); transform to mild--severe depression?
- This will lose power over using PHQ-9 scores
- Most powerful approach: correlation analysis of two ordinal (or almost continuous) predictors
- Spearman rank correlation test on PHQ-9 vs. SIBD-Q score; quote Spearman rho and P-value
- Also graph raw data (scatterplot)
Warren Clayton, Medicine - Endocrinology
- Gestational diabetes
- n=150 outpatients in registry (120 with complete lab data); followed dx to delivery then 6m post partem
- Lab values vs. pt required meds to treat gestational diabetes; also interested in whether child was born with macrosomia
- Compare HbA1c
- Mother total weight gain vs. need for med, and vs. macrosomia (> 4000g)
- More power to treat birth weight as a continuous variable
- If doing a parametric analysis (as opposed Spearman's rho or Wilcoxon test), need to analyze HbA1C on the reciprocal scale
- Could use regression spline to estimate the shape of the relationship between HbA1C and birth weight
- Start with scatterplot
- Model: Probability of needing medication = function of HbA1c, total weight gain
- Model: Birth weight = function of HbA1c, total weight gain, mother original weight
- May be good to also try to get mother's height (or BMI)
- Do post-partem reminders (all women had these in this study) increase the likelihood of woman returning for follow-up?
15 November 2010
Taneya Koonce, Becky Jerome, EBL Knowledge Management
- ED pts with hypertension; educational intervention RCT
- 2w post ED visit: hypertension knowledge; 16 questions 0-100 total score
- Hoping for a 10-point difference in total scores on the average
- Completed pilot sample in ED to get SD = 13
- Used PS, power=.8: N=56 total (both groups combined); may want to run with power=.9
- Alternative: margin of error (half-width of 0.95 confidence interval)
- Able to estimate the unknown true margin of error with 0.95 confidence to within a margin of error of +/- 7
- Note that if the confidence interval (mean difference +/- margin of error) excludes zero, that corresponds to rejecting the null hypothesis at the 0.05 alpha level
- If were to quadruple the sample size, the margin of error would be reduced by a factor of 2
- May be useful to plan around a parametric test (two-sample t-test) but to actually use a nonparametric test (Wilcoxon-Mann-Whitney two-sample rank sum test)
25 October 2010
Andrea Brock, SOM
- Try graphics in R (www.r-project.org)
- Advise against percent change as a method to normalize data. Try instead to plot all raw data (e.g. spaghetti plot for each coordinate). Bland-Altman plot of percent change against geometric mean of the two points (should look like a band of noise) to assess adequacy of percent change method (over- or under-normalizing).
- Regression modeling strategy may include adjusting for baseline measure (not percent change).
- Recommend setting up spreadsheet with ID, species, xmm, ymm, time, depth (i.e., tall and thin format).
- Further, Python can be used for advanced graphics (http://matplotlib.sourceforge.net/examples/mplot3d/subplot3d_demo.html).
18 October 2010
Elizabeth Moore, Nursing
- Early mother infant skin-to-skin contact Cochrane Review post-birth: 15-30 minutes up to 2 hours. Outcomes: breastfeeding, physiologic stability, infant behavior crying, mother behavior. ~30 different studies; however, outcomes have wide range of measure (not consistent).
- How combine different outcomes in meta-analyses? Building a model with temperature as outcome and study variables (e.g., location and lag time) as covariates. Possible to ignore location of body temperature (assuming all are unbiased)?
- Software: BUGs or JAG for Bayesian meta-analysis.
- A Forrest plot will graph all estimates from multiple studies and their uncertainty on one axis. A funnel plot is a useful graph designed to check the existence of publication bias in meta-analyses.
Vic Cain and Bob Levine, Meharry Family Community Medicine
- Examined heart failure by age, race and sex (TN discharge data). Statistical reviewer recommended Poisson model with population rates as offsets. Reported age-adjusted rate per 100,000 for Tennessee.
- Using standard regression, perform a goodness of fit test and examine residual plot (departure from predicted to true value). If variance changes with size of mean, then Poisson may be more appropriate. * Poisson for each combination (ex.:age, race, sex, time), how many have their heart diseases, create a summary dataset and do modeling based on this dataset.
Nita Farahany, Law
- Criminal cases with neurological assessment with the purpose of decreasing the charges. There few cases with evidence of use.
11 October
Paul Murphy, SPED
- Trying to measure comprehension in 8th grade African-american inner city schools in Social Studies.
- as function of writing intervention (treatment); control groups will have exposure to readings, tutorials.
- treatment also includes dictionary lookups of difficult materials
- students highlight sections with which they have difficulty;
- D-prime score based on probes at different points during treatment
- several predictors of score: self-relevance, interest, topic, reading comprehension, fidelity of treatment measures
- D-prime can measure different types of comprehension
- can make predictions about how scores may change according to interventions
- recommend building predictive model of scores, and estimating slope parameters of treatments
- examine models with random intercepts and pre-treatment effects
- refer to Gelman and Hill "Data Analysis Using Regression and Multilevel/Hierarchical Models"
4 October 10
Amanda Salantiro, Medicine
- Prospective study of 3000 patients for 3.5 years (minimum of 1 year). Social determinants of health on readmission and mortality.
- Need help adjusting sample size calculation for a new population with higher incidence and mortality.
- Prior sample size used Cox Proportional Hazard model with Weibull distribution (accommodates two survival time points).
- From prior literature, we have 30 day survival for men and women in this new population. Could weight these two estimates based on expected number of events for male and female to have one number summary for 30 day survival.
Elizabeth Campos Pearce, General Surgery -- Otolaryngology
- 15 years of data - 22 patients that have surgery and surgery+radiation with 10 year metastases (recurrence) or death endpoint.
- Combined endpoint of recurrence or death (recurrence-free survival time). Some patients are lost.
- Focus hypothesis around hazard ratio comparing survival in both groups (rather than 2 year survival, 5 year, etc.), using the Cox Proportional Hazards model.
- Make sure to report the confidence interval around the hazard ratio.
- Generate a priority list for testing hypotheses driven by clinical understanding (not influenced by looking at data). This may be a better approach then adjusting for multiple comparison.
- Excel is okay for data entry, but long term may want to use RedCAP. Statistical packages include R (free), Stata, SPSS, etc.
20 September 10
Lisa Lachenmyer, Pediatric Urology
- Parental anxiety for parents with children having radiology treatment
- Looking for best way to educate families about test, and how to prepare for it
- Two groups receive survey, treatment group given reading materials
- Measuring via state trait anxiety (STAI) questionnaire
- Unpopular with parents study in urology due to use of catheter
- Groups consist of both those who have or have not gone through the procedure before
- Control group receives minimal description of procedure, but may have received information from their pediatrician if not from Vanderbilt
- Interested in sample size estimation
- need to know about baseline anxiety measure
- such scores are often used as a covariate, less commonly as response measure
- scores tend to be coarse measures
- need to balance age of children in treatment/control groups. (parents?)
- can get a very coarse estimate of n, assuming a simple comparison of proportions, but the expected effect size will probably be far to small to detect without considering covariates
- project is unfunded
- IRB application is forthcoming
13 September 10
Merida Grant, Psychology
- In SPSS, when running Cox Proportional Hazards, use ROBUST standard error estimates. Exp(beta) is the Hazard Ratio.
- When using additional covariates, sample size reduces because cases with missing values are DROPPED. This 'complete case' approach is potentially biased because we reduce the population to those without missing data; consider missing data methods (e.g., multiple imputation). In multiple imputation, we predict missing values of covariates using all other data then run regression, we repeat this procedure ~25 times, then average all model estimates.
Ileko Mugalla, Institute for Global Health
- Focus Group of Burmese Refugees in Nashville.
- services from community - perception, experience and benefits (all qualitative)
- demographics (only quantitative)
- 4 separate focus group sessions with same group of individuals (6-12)
- Level of statistical support depends on study aims - sounds descriptive in nature (not requiring advanced analysis).
- Could consider reliability methods for coding qualitative data.
- Check Peabody for good contacts on coding interview data. Bahr Weisz has cross-cultural expertise in qualitative study.
- Consider the survey and community core research groups. Warren Lambert (Kennedy Center) may refer Vanderbilt qualitative researchers; come to biostatistics clinic on 9/14. VICTR funds applied for by Carol Etherington through VIGH, "Assimilation and empowerment of newcomer refugees in Nashville".
30 August 10
- Discussed methods for creating web seminars
- Slide show production with audio track - need more information
- Discussed an economist's criticism of ANCOVA in randomized experiments
16 August 10
Uche Sampson, Cardiovascular Medicine
- AAA = abdominal aortic aneurysm
- Goal: risk prediction for rupture of AAA
- PET scan 14 patients; arterial wall inflammation in wall in which aneurysm is present
- Also looked at cytokines
- Growth rate of aneurysm; < 10 mm/y
- ultrasound or CT scan yearly
- Want to extend to more heterogeneous groups including fast-growing aneurysms
- Broaden biomarkers, predict rate of growth
- Age and smoking are strong
- Dimension of biomarkers: cytokine panel (IL 1-10, TNF); perhaps 50 candidates
- Sample size may focus on PET - predictive power on progression/adverse events (first aim)
- Distinguish goals of discovery vs. accurate prediction
- Using animal models to simultaneously understand proteomics of biomarkers
- Sample size philosophy:
- make Y as fine as possible; linear rate vs. longitudinal analysis of multiple points
- sample size to achieve same accuracy in the future as we estimate when the first group of patients is collected
- 15:1 rule (patients:candidate dimensions of predictors); may be less demanding if serial measurements are not very redundant
- If within-patient correlation is 0.5, lots of observations per patient makes the patient equivalent to about 2 independent patients (assuming exchangeable correlation pattern, i.e., compound symmetry)
- Likely to use CT scan for monitoring patients
- Global statistical design: longitudinal data analysis
Baqiyyah Conway, Epidemiology
- Mortality in type I diabetes; does socioeconomic status (SES) adjustment get rid of racial differences?
- Differences in access to health care - demonstrated in comparisons with Scandinavians
- African Americans have 2-3 times mortality rates compared to Caucasions with type I DB
- AA type I DM vs AA gen pop: excess mortality similar to comparison of white type I DM vs white general pop
- But mortality in AA is mostly DM related
- Most US studies have poorly controlled for SES
- Southern Community Cohort Study; southest US, mostly low income; most have access to health care
- Have insulin usage status at enrollment but not insulin hx; do have age at diagnosis
- SMR using Cox models, age as time scale
- Whites have significant shorted f/u time (recruitment of whites pushed years after study start)
- Entry age = baseline study age
- Covariate = duration of DM and follow-up time
- Education categories may be too broad (problem with residual confounding)
- No reason not to use ordinary Cox model with t=0 being time of enrollment and subject characterization
- Cox model easily allows for follow-up time to depend on subject characteristics
- Can adjust for secular trend (using date of enrollment as a baseline covariate)
- Are there any combined income/education SES scales that should be used?
Merida Grant, Psychology
- See 2 Aug 10
- Working with a demographer on a dataset on teens to early 20s, focusing on stress, depression+
- 1800 subjects mostly 19-21y; subjects found in representative south Florida cohort
- Second wave of data to follow forward
- Are there time periods of concentrated risk?
- Stress sensitization (hyper response); brain changes during discrete periods
- Interested in risk of first onset of depression
- How long from period to first onset (lag time)?
- Brain morphology, physiology
- Retrospective recall of trauma (33 forms)
- Simplest Cox model (one past event): time since event if it occurred, presence of the event, interaction of the two
- Will only include those having depression
- Not so interested in current depression status
- May be possible to form separate follow-up intervals for each event for each subject, put them all together with adjustment for intra-cluster correlation
- Should be individuals with episodes of depression but no past trauma
- Best to not create time/age intervals but to use all times to the nearest year of age
2 August 10
Merida Grant, Dept. of Psychology
- Looking at relationship between severity of childhood trauma and fMRI activity
- Found that depression itself did non increase activity level but early life trauma did
- Interested in how to compare slopes of two models.
- Each subject took two questionnaires dealing with sexual and physical abuse.
- Fit model:
- activity ~ intercept + alpha*sexual abuse + beta*physical abuse + theta*interaction
- activity ~ intercept + alpha*abuse + individual random effect
- Look at parameter estimates and standard errors
Patrick Jones, Pharmacology
- Studying the molecular genetics of how mosquitoes smell
- logit(y) ~ Beta_0 + Beta_1*x, where x is an indicator for cell line
- Generalized LInear Model with binomial errors
- logit(y) = log(y/1-y)
19 July 10
Merida Grant, Dept. of Psychology
- Eye tracking equiptment to monitor attention
- 2 group (high- and low-symptomatic) x 4 valences (neutral, fearful, sad, happy)
- response variables: fixation %, fixation duration, maybe latency to deployment
- trials 3000ms in duration, 6 trials per epoch
- interesting effects may be getting drowned out by individual-level variation
- rather than average over all individuals within each group, we can employ an individual random effect
- individual random effect will tend to attenuate the magnitude of the fixed effects, but allow more subtle effects to be revealed
- See Ayumi Shintani's course on fitting mixed effects models in SPSS: http://biostat.mc.vanderbilt.edu/wiki/Main/MsciBiostatII
21Jun10
Thomas Andl, Dept. of Medicine
- Cells treated with control and inhibitor (3 wells + 3 wells)
- 10 repeats (new experiments / new day)
- 3 technical replicates per day
Wild Type Test
---------------- ----------------
Control Inh Control Inh
10*3 rows (3 technical reps x 10 days) - Take log of any raw data point (cell count)
- Need to decide between ordinary model and Poisson regression (which is ideal for counts under certain circumstances)
- Need to state hypothesis in general terms, e.g., in a clinical trial with treatments A and B we might want to test whether the treatment effect is the same for males as for females (H0: no treatment x sex interaction)
- In the current setting, the interest is in a differential inhibition effect for WT vs. test
- Multi-level hierarchical model would efficiently use technical replicates and properly treat them as "within" day to day replicates; it can also handle imbalances
- A suitable dataset for such a model would look like (long and thin format):
genotype treatment day techrep count1 count2
WT C 1 1
WT C 1 2
...
Test1 I
...
Test10
(many duplicates of genotype and treatment columns) - Interested in testing each genotype vs. WT (separately)
- E-mail biostat-clinic@list.vanderbilt.edu
Jessica Moore, Dept. of Medicine
- Reviewer recommendations: 1(reject) - 5 (immediate accept)
- Author-suggested reviewers vs. reviewers assigned by AE
- Look at cases where AE chose a suggested reviewer vs. didn't
- How does this affect the Editor's decision?
- Data collected: J Am Soc Nephrology 6m period; n=200
- Find out if there are IRB issues; discuss with Elizabeth Heitman
- 100 papers had recommended reviewers who actually made recommendations
- Avg. of 3 reviewers/article; can be 1-6
- Looking at recommendations of non-recommended reviewers
- May need to find out more about author characteristics and perhaps reviewer characteristics
- Are junior researchers more likely to request certain reviewers?
- Unit of analysis could be a review for some purposes
- May need intra-cluster correlation adjustment (each paper could be a cluster)
- Need for adjustments depends on how much you are inferring from the specific to the general (other journals? same journal but different time spans?)
- May elect to be purely descriptive
- Confidence intervals may help quantify margin of error but have to then envision the 'population'
- Best to treat the 1-5 response variable as an ordinal variable
- Methods that only use ranks include the Wilcoxon test, Spearman's rank correlation, proportional odds ordinal logistic regression model
- Don't trust SPSS to pick the "right" method for ordinal data
14Jun10
Carl Frankel
- Dataset confirms that children as children stutter more, sentences are smaller.
- Kids who have more appraisals tend to stutter more, have smaller MLUs.
- How to explaiin confounding factors to researchers?
ZhongJiang Zhou, visiting scholar in Cardiology
- Interested in learning statistics
- Could join Cardiology journal club.
07Jun10
Ben Hornsby, Hearing & Speech
- Pilot data looking at benefit of hearing aids in different situations; subjective measures and objective data on about 20 patients, using two main questionnaires
- Suggest proportional odds (or "ordinal") logistic regression to look at GHABP questions with 0-5 integer outcome, perhaps with random effects (include all four scenarios in one model, using patient as random effect; take most advantage of data from 20 patients)
- For Profile of Hearing Aid Benefit, perhaps take similar random effects approach, in order to get an idea of patterns rather than just overall scores
- One important covariate results in a distribution for each patient; need a way to summarize in one/few values (maybe number, like quantiles; maybe skewed left/right/not skewed; other possibilities)
- Suggest possibility of VICTR voucher to get help with more complex analysis
26Apr10
Rachel Hayes, Bioinformatics
- Graphics questions
19Apr10
Hornsby, Hearing & Speech Sciences
- Hearing loss under a variety of conditions, especially interested in high pitches
- 10 conditions, subject tested twice under each condition (averaged), order of conditions randomized over subjects
- Total score based on 100 key words per condition
- 62 subjects; each had all 10 conditions in 1-2 sittings; all had had some hearing loss, with similar hearing ability in the two ears
- Measure frequency thesholds, averaged
- Audibility index - math model that predicts performance as a function of pitch
- Regression model total score in given filter condition = low freq loss + high freq loss + age + predicted score
- Fit in each of the 10 conditions; 62 rows of data in each regression
- Referee comment concerning problems of having multiple predictors correlated with each other:
- Only a problem if the model isn't consistent with the causal pathway, if don't try to interpret competing pieces of the model separately
- Was interested in the difference between high and low (focusing on sign of coefficients)
- Hypothesis: subjects with steeply sloping hearing loss are less able to use high frequency information than someone with a flat loss but similar high frequency thresholds
- Is it possible to parameterize the relationships in Figure 1 to better capture this?
- How about assuming a function of frequency, and estimating the total score as a function of this shape?
- Could envision an average shape over subjects within condition
- Could fit this curve using many non-independent observations
- Get a confidence band for the estimated f(frequency)
- Dataset would be tall and thin with variables for subject ID, condition, age (duplicated), frequency, total score (duplicated within condition if wanted to put the 10 together)
- Addresses reviewer's comment "Further, using thresholds at specific frequencies that were applicable to the filter bands in question would be more relevant predictor variables than averages across arbitrarily determined ranges."
- Regarding the stepwise regression issue: it may not be helpful to allow variables to move in and out of the model
12Apr10
Huck Muldowney, Cardiovascular Medicine
- Statin treatment to decrease incidence of DVT or PE in a high-risk cancer population
- Involves Slosky and AstraZeneca
- JUPITER studied older patients; stopped early for reduced risk of MI; also found decrease in DVT over placebo
- Other data, more cherry picked, reduced admission for DVT (0.21 vs 0.08)
- Cancer patients have 4-fold incidence of DVT/PE over general population, chemotherapy increases this by up to another factor of 6
- California insurance registry: 3% DVT incidence in first year
- Target pts with invasive cancer requiring chemotherapy
- Composite endpoint: all-cause death, superficial venous thrombosis, DVT, PE
- Don't expect many deaths in the first year due primarily to the tumor (more for ovarian ca)
- No available markers of precursors for DVT or PE
- Estimate of one-year incidence of combined events: 6%
- Want to detect a reduction down to 4%
- If time to event was not considered and patients were only followed 1y, 5000 patients would be needed to have 0.9 power to detect this difference
- 3y follow-up may be possible; watch for interruption of follow-up for events of interest by events not of interest (pure ca deaths)
- May consider adding AMI to events
- Is it possible to do a very large simple trial with a 3m follow-up period?
- Possible to piggyback onto another cancer trial (e.g., 2x2 factorial design)?
29Mar10
Aihua Bian, Nephrology
- Has missing data for mice study - non-ignorable missing
- Pattern mixture model recommended
22Mar10
Ehab Kasasbeh, Cardiology
- Mentor John Cleator
- Dog study -- emailed data to Biostat Clinic previously.
- Has ~4 dogs in a non-trt / trt scenario (each dog is paired with itself).
- Measuring various outcomes over time (eg, 30 second intervals).
- Wanting to know if significant difference between non-trt & trt.
- Issues: what primary outcome is appropriate (ie, wanted to use % change); variability among and across dogs; small number of dogs.
- Recommended he submit a request for a Voucher.
Mario Rojas, Neonatology
- Wanting Vandy & another institute to get involved in a RCT currently happening in South America.
- Looking at the immunity of very low birth weight babies (< 1500 grams) in NICU -- probiotics and antibiotics.
- Wanting a sample size to conduct a sub-analysis comparing babies exclusively breastfed, to babies partially breastfed, to babies exclusively formula fed.
- Asked him to get some more distribution information of the primary outcome in the three groups so we can formally calculate the sample size needed.
8Mar10
M. Pugh and A. Hemnes, Pulmonary
- Metabolic Syndrome and Pulmonary Hypertension Disease
- Applied for money through VICTR
- Studying ten patients before and after gastric bypass surgery.
- Pilot data for a larger study
- Calculate confidence intervals of endpoints
William Swiggart, Internal Medicine
- Developing a way to teach screenings for substance abuse
- Web-based program
- Planning to study 100 individuals - med students, residents, attendings
- Interested in improving prescribing habits
- Some individuals learn how to take tests
- They could learn from just taking the survey
- Stagger intervention in departments and see if outcomes are staggered as well.
- R18 grant
- Recommend describing it as exploratory to gain information for an R01 grant later
- Chart reviews would be a great second step for the R01 grant.
1Mar10
Xian Ho, Biomedical Informatics
- Likert scaled data - ordinal
Jayant Bagai, Cardiovascular Medicine
- Patients on heart-lung machine in the cardiac catheterization lab
- Is there a benefit to a new device
- 39 patients
- Use EUROSCORE to measure baseline patient risk based on previous cv surgery, male, pvd, shock
- Mortality study would have low power
- Small sample size prevent regressions analysis
- Best to present data as case series with descriptive statistics
8Feb10
Carl Frankel, Psychology
- Question about factor analysis: how many independent observations should there be per factor
- Jim Steiger's approach: bootstrap
Buddy Davis and Kurt Niepraschk, Orthodontics
- Radiographic measurements (angular, linear)
- Measurements are made for one patient without knowledge of the normal positioning
- Comparing observers' measurments with the norm ignores normal variation about that norm
- Test-retest values would be helpful (technical replicates; intra-observer variability)
- 3 measurements may be measuring the same factor
- Sharon Phillips will likely be at the Wednesday clinic (supports Surgical Sciences)
- Follow-up e-mail to biostat-clinic@list.vanderbilt.edu; can attached HIPAA-compliant spreadsheet unless there are data that are sensitive for pure research purposes
Lin Ge, Visiting Scholar Pediatric Urology, advisor is Neil Bhowmick
- Tissue array data (oral cancer)
- Want to see if tumor size and metastasis (ascertained by other means) can be predicted from characteristics/measurments from the staining process
- Response variable is tumor grade or presence/absences of metatastisis or a global ordinal
- 0=no cancer 1=trace 2=moderate 3=proliferative 4=metast.
- Ideal situation: a few stain quantifications and a strictly ordinal or continuous tumor outcome measure (TNM stage/grade)
- Could also include subjective stain interpretations
- Multivariable regression setup
- Adjust for age, sex, organ
- Ran Kruskal-Wallis test (combined some grades and did not make use of ordering of grades); Y=stain intensity + error
- Problems: reversed independent and dependent variables (not a severe problem) and cannot incorporate age, sex, etc.
- Samples from 89 patients from company providing the tissue results
- Contact Yu Shyr PhD, chief of Cancer Biostatistics. Alternates: Sharon Phillips (adult Surgical Sciences), Ben Saville (Pediatrics)
1Feb10
Na Wang and Ping Ping Bao, Epidemiology
- Time to death in a 90,000 subjects; 2500 deaths due to liver cancer
- Violation of proportional hazards assumption by introducing log(time) by covariate interactions as time-dependent covariates (7 cov.)
- Significant interactions for 4
- Need to look at the magnitude of the non-proportional hazards by plotting the log hazard ratio as a function of time
- will be of the form overall log hazard ratio + differential log hazard ratio * log(t); plot vs t; plot from 0.01 years to 15 years
- do this for 4 significant variables
- Assumptions can be violated but a model can be useful; changing to another model results in worse violations of ITS assumptions
- Need to look at overall structure of survival
- Take the most significant prognostic factor and plot log(-log(Kaplan-Meier estimates)) over time by 3-4 strata created from that factor
- May repeat for 2 other prognostic factors
- Judge whether curves converge or diverge -> different models may need to be considered other than Cox PH (e.g., accelerated failure time model)
Trent Rosenbloom and Jack Starmer, Biomedical Informatics
- Observed/expected mortality ratio in clinical outcomes quality
- Some groups have small # patients (10 or so)
- General problems with obs/expected ratios
- Best to consider logistic regression model with specialty/physician
- specialty has 33 levels; consider as random effects in a mixed effects binary logistic model
- adjustment for baseline risk automatic (fixed effects); these would include the variables used in the "expected" model
- as a backup plan if individual covariates are not available, use the logit of the expected risk (log(p/(1-p))) as a regular covariate or as an offset (if assume slope is 1.0)
- Obtain a relative odds for each specialty vs. a reference group (regression coefficient = log relative odds)
- The random effects aspect of the model causes shrinkage; large specialty's data are 'trusted'
- Reporting can include shrunken odds ratio, confidence limits, and ranks (with confidence limits)
- Bayesian modeling can also allow reporting of Probability(odds ratio against the median odds of all specialties > 1.2)
- approach suggested by Sharon-Lise Normand of Harvard; Tom Louis of Johns Hopkins
- See http://www.amazon.com/Bayesian-Approaches-Health-Care-Evaluation-Statistics/dp/0471499757/ref=sr_1_1?ie=UTF8&s=books&qid=1265049891&sr=8-1
- More thought could be put into handling multiple hospitals and specialties simultaneously
- Optimum situation is to have individual patient data from all specialties/hospitals
Rachel Idowu, Surgery
- Came to last Wednesday's clinic
- Survey to learn about understanding of trauma preparation for disasters
- 31,049 paramedics/trauma physicians surveyed; 15% response rate for pre-hospital 4091, trauma (in-hospital) 591
- Need to do everything possible to characterize subjects who responded compared to the entire population of subjects
- Determine what the Am Coll Surgeons is willing to provide in aggregate about the 31,049
- For respondents, interested in predictors of probability of correct responses
- Can predict the number of correct responses per subject (0-14) using proportional odds ordinal logistic regression as mentioned by Jeffrey Blume
- Sample size will also allow separate regressions (binary logistic models) on each of the 14 questions
25Jan10
Joan Isom, Infectious Disease
- www.randomization.com
- We used the first (and original generator).
- Use the seed to make list repeatable.
- Using blocks assures the treatment assignments will be balanced throughout the course of the study. For example, using 10 blocks of size 4 will created 10 blocks with 2 As and 2 Bs in each block.
- Keep the evaluators "blind" to the patients treatment assignments.
Peggy Kendall, Allergy
- Sample size for comparing incidences of antibodies in the pancreas and the islets.
- Select a single type of antibody to base the sample size on. For example, focus on VK1s, and decide that the what the least difference is you would not want to miss being statistically significant. Then, center this difference around 50% to be conservative. If a difference of 15% is the least difference, use standard sample size software to determine the sample size needed to compare 50% to 35%.
- Complicating the problem are the many comparisons you will run on this dataset. To compensate, you will need to inflate this sample size by 15%.
- Additionally, if it takes 1 in 1000 samples to find a specific antibody, you will need to take the already inflated sample size by 1000 times to assure adaquate samples will be found.
- Due to the shear number of combinations of heavy and light chains of the antibodies, we recommend returning to a Tuesday clinic where they can assist with the high dimensional aspects of this problem.
18Jan10
Dan Ashmead, Jeremy Schepers, Wes Grantham, Dept. of Hearing and Speech Sciences
- Car sounds and pedestrians esp. blind pedestrians
- Anechoic chamber
- 3 Listening tasks: alignment, gap perception, speed
- Find a threshold for the amount of something (e.g., misalignment) that can be perceived
- Staircase approach, increasingly more difficult but when miss a perception make the task easier
- Take average of replicates
- Not clear how to relate to actual pedestrian performance
- Considering 4 age groups; omitting very young and teenagers
- Include visually impaired subjects; need to not bias sample towards extremely independent visually impaired subjects
- Stimulus-related variables
- "add-on" sound, internal combustion sound
- background sound: amount of traffic, rain, winter conditions
- Cannot have equal representation of all cross-classification of conditions
- Suggest using an additive model (except for certain interactions with visual impairment) to minimize sample size
- Assume a dose-response continuous relationship for age; a quadratic relationship may be reasonable
- Target might be the performance at the worst age
- Most likely interactions: background noise and older age; age and visual impairment
- Recruiting problems for younger subjects
- Can recruit over a wide age range and later shut down recruitment for certain age ranges that are over-sampled
- This does not require prior knowledge of the population age distribution but does assume that the order in which subjects volunteer is not associated with their detection thresholds
- Complexity of model could be informed by what subjects are recruited
- Response variable is a threshold - how fine a difference can be discriminated
- How to figure sample size? A rough rule of thumb is to specify the model, count the number of needed parameters, and multiply by 15
- Parameters: overall intercept, slope of age, slope of age^2, sound type, rain, ..., + interactions between variables
- If a key quantity of interest is the comparison of visually impaired vs non-visually impaired, an optimal sample would balance on the sample size in these two groups
- Or: have enough sample to speak to the question about non-visually impaired, and enough to provide a rough estimate for visually impaired
- Account for repeated measures; each subject may receive 4 or more conditions
- Assume equal correlation between responses from any two conditions
- Effective sample size arising from repeated measures within subject is hard to determine ahead of time; depends on how high is the intra-subject correlation
- Is there a need for a global objective function to optimize that includes driver perception of add-on sound?
4Jan10
Eli Poe, Research Assistant in Gen Peds working with Shari Barkin
- Interested in how the clinics work
- Working in behavioral research in the community, e.g., healthy lifestyle; pre-post + control group
- Data in Excel (for checking data) but originate in REDCap; use Stata and SPSS
- Terri Scott runs a REDCap clinic
- Ben Saville covers the Dept. of Pediatrics in general
- Talked about course opportunities: IGP 304, BME (undergrad), MSCI (Dan Byrne and Ayumi Shintani)
- Recommended William Dupont's book; also look at Kirkwood & Sterne's book Essential Medical Statistics
- Friday Clinical Research Center VICTR methods workshops at 9-10a
Carl Frankel, Psych
- Continued the discussion of parametric vs. nonparametric statistics
- Feels that nonpar. stat. may be more appropriate in behavioral assessment
- What is the nonpar. analog of mixed models for repeated measures data?
- See Hedeker's work, e.g. http://tigger.uic.edu/~hedeker/mix.html and possibly the
glmmPQLfunction in R'sMASSpackage - Another approach: fit ordinary PO model ignoring complexity of repeated measures, then use after-the-fit correction for intra-cluster correlation (cluster sandwich covariance estimator or cluster bootstrap)
21Dec09
Mandy O'Leary and Yi Wei Tang, Pathology
- HPV genotyping, cytology
- R dataset attached https://biostat.app.vumc.org/wiki/pub/Main/GenClinicAnalysisArchive/tang.rda here
- R code to create dataset, plus R code used during clinic:
gen <- subset(tang, select=hpv6:hpv86) v <- varclus(~., data=gen, sim='bothpos') plot(v) with(gen, table(hpv16, hpv52))
cyto <- subset(tang, select=atypical.cells:large.groups) pos <- sapply(cyto, function(x) any(x > 0)) cyto <- cyto[, pos] v <- varclus(~., data=cyto) plot(v)14Dec09
Kylee Spencer, MPB/Center for Human Genetics Research
- Genetics of macular degeneration
- Cases & controls from VU Ophthalmology
- Independent test dataset from Memphis (ARMA)
- Logistic regression, MDR, GENN
- Could consider the use of ordinal logistic regression, as a 1-5 grading is available
- Analysis to date uses a binary present/absent diagnosis
- VU data split training + test
- Split-sample validation can be unstable
- There are advantages to not splitting the data and using the bootstrap
- Maximal adjustment for age could be obtained using a restricted cubic spline
- could adjust for spline(age) x sex interaction
- http://biostat.mc.vanderbilt.edu/wiki/pub/Main/RmS/logistic.val.pdf simulates various validation strategies
- Choice of accuracy index is all-important
- http://biostat.mc.vanderbilt.edu/wiki/pub/Main/FHHandouts/FHbiomarkers.pdf contains an example where % classified correct makes one select the wrong model
- ROC area (C-index) is an improvement but it is not fully sensitive
- See course notes: http://biostat.mc.vanderbilt.edu/wiki/pub/Main/RmS/rms.pdf
- Estimation of upper limit of predictive ability: use a reliable black-box technique (SVM, random forests)
30Nov09
Amanda Solis, microbiology and immunology
- Raw data % of green viruses that are also red. Want to compare wild type to mutant. Fold change is wild type/mutant. Consider not normalizing. Simple way - logistic regression using covariates for type and experimental day; outcome is binary - red/not. Interpret model via OR magnitude (not statistical significance) and confidence intervals.
- This approach may be open to criticism because unit of analysis is virus.
Randi Kauffmann, Surgery
- Procalcitonin (PCT) - biomarker for infection in patients with surgical interventions
- 18 trauma patients w/orthopedic proc for 7 days from admission.
- Longitudinal data with varying rates of infections and day of procs/dx
- Response feature (two-stage) analysis
- linear regression per-patient gives one slope estimate (e.g., change in PCT) per patient
- then use this as a covariate in logistic regression
- Grade trauma/intervention as a covariate, outcome is Infection Yes/No, unit of analysis is patient
- Spaghetti plot with PCT versus day and color code
Rikki Harris, Psychology
- National Study of Youth and Religion - cross-sectional study of families, children and parents (includes substance abuse and violence). Youth aged 12-17, religious identity, parental religious identity, substance abuse and violence. Factor analysis/principal components good for cross-sectional survey data.
- Psychometric analysis - might look up Irene Feurer or some Peabody faculty.
- If dichotomous outcome, use logistic regression.
23Nov09
Fernando Ovalle, SOM 2nd Year
- Neurosurgery; arteriovenous malformation (AVM): abnormal connection skipping a capillary. Causes pressure problem and poor O2 distribution to related tissue; risk of aneurysm, stroke, etc.
- Glue injection through catheter to wall off malformation, later cut
- Database of patients dx with AVM and treated with embolization
- Perfusion pressure breakthrough is a complication of major interest; causes bleeding in brain, or fluid build-up
- Later neurological symptoms, dx by CT scan
- May be caused by too quick glue injection
- What factors are predictive of this complication?
- Candidates: volume of glue injected, % of remaining AVM obliterated, % of total oblit., size of AVM, procedure timing, ratios of these variables
- N=70 patients; 7 have the complication
- Keep as a cohort study; don't use matching
- 7 events is too few for a reliable analysis of one pre-specified risk factor
- Limiting feature in any analysis is the number of events, not the number of patients
- Rule of thumb: 15 events per single potential predictor
- Roughtly speaking, here one could analysis one-half of one predictor
- Need a pre-clinical complication marker, more patients with the event, or answer a broader question using different types of complications
- t-test (better: Wilcoxon test) could be done if there were a single pre-specified predictor (with no confounders to adjust for)
- Could make a descriptive paper with no P-values or confidence intervals
Victoria Werster, SOM 2nd Year
- Peds ID - periodic fever syndrom (pfapa) occurs rarely. Follow up (N=60) patients from 10 year-old study to determine if negative outcomes occurred in past 10-12 years following treatment of pfapa with prednizone (1 dose).
- Outcome, patients with/without fevers (~9 still do). Similar problem to Fernando's listed above; that is, too few events.
- Could consider time to event analysis or incidence rate. Depends on follow-up time.
- This might be problematic as the date of pfapa resolution is unknown.
- 95% confidence interval of proportion = p +- 1.96*se (normal approximation) where se=sqrt(p(1-p)/n)
16Nov09
Elias Haddad, Cardiology
- Randomized trial with low dose asprin - coated versus chewable over course of 2 years. Response is thomboxane level (platelet activity). Well matched arm except weight circumference.
- Significant for un-adjusted test. Is adjusted p=0.065 significant enough for clinical relevance? N~100
- Present adjusted result as is, but devote some discussion to recommendation. Concern is that p>0.05 will lead to ignored result by pharma/readers.
- Can we adjust for less predictors?
- Can we collect more data?
- "Spent" type I error by looking at data. How determine magnitude of patients for 2nd round of accrual? Rather than this concern, determine # of patients to accrue and detail actions in trial summary - no need for "sequential adjustment". Power follow-up study with reasonable power then combine data.
- Easiest solution w/least amount of criticism - power and run a new study. Might then combine both studies via Bayesian approach.
- How present table 1?
- Show confidence intervals (okay to include p-value) to demonstrate that randomization was good.
- Significant for un-adjusted test. Is adjusted p=0.065 significant enough for clinical relevance? N~100
Randi Kauffmann, Surgery
- Multi-drug resistant infection rate is outcome. Collected patient days/admits and infection data (exposure). For a quarter, ~2200 patient days w/ ~9 infections. Do not have patient-level data (only summary over quarter).
- Use patient days or admits as unit of observation?
- If unit of analysis is patient - good argument for using admissions.
- Longer length of stay is increased exposure, but patient days are not independent.
- nbreg mdr_infxs pre_post_intrv, dispersion(mean) exposure(patient_days) irr
- Use patient days or admits as unit of observation?
09Nov09
Bart Masters, Biomedical Engineering
- Studying fluorescence and temperature
- Needs help with sample size justification and analysis plan
Tom Talbot, Infectious Disease
- Studying Ventilator-Associated Pneumonia in Adult ICUs and adherence to practices
- Needs help with time-series analysis
26Oct09
Monica Hanson, Pharmacology
- Comparing preliminary BAL culture results to post, to test for accuracy for the purpose of tailoring medication
- Two prelim results, 24 and 48 hours, confirmed at 72 hours
- Can they make a reliable decision earlier at 24 or 48 hours?
- Typical study compares to gold standard
- Binary outcome
- Need to know the goals of doing sensitivity/specificity analysis
- Estimate of variability in machine; callibration should be included in pamphlet associated with it
- Statistically, prospectively would be easier to analyze than retrospective
- Recommended getting a CTSA voucher
Amy Pennington, Pharmacology
- Began a pharmacy counseling service on Warfarin, blood thinner
- Patient education has shown better outcomes
- Part of education is reconciling patient drug records with actual use
- Some studies have showed that Vanderbilt scores low in the number of patients receiving counseling (~0%)
- Previously hadn't provided counseling
- Goal is to show patients are now receiving counseling
19Oct09
Pierre Massion, Pulmonary at Cancer Center
- Early detection of lung cancer
- validate biomarkers of lung cancer risk (esp. related to lung cancer incidence)
- prospective cohort study - suggested in studio with JeffreyBlume
- If patients at higher risk have more opportunities to show they have the disease, will add verification bias into study. Verification bias = gold standard is not independent of test.
- The gold standard definition should be independent of the study design
- Suggest getting rid of nested case/control study
- Only has data on all three risk groups (low, intermediate, high) at years 0,2 and 5 based on standard of clinical care.
- Should also have an analysis chart of which timepoints analysis will be performed for which all ppts receive surveillance (e.g. baseline, 9-12mo, Y2 and Y5). Allows for easier visualization of which comparisons will be made.
- Developing gold standard is problematic when not all ppts are imaged. Growing nodule (from baseline) determines whether ppt undergoes biopsy, bronchoscopy, or surgery. Stable or no nodules means no lung cancer (no procedures).
- Can assess 1 year, 2 year and 5 year cancer risk since gold standard may be ascertained for these time points.
- Biomarkers will be measured on frozen serum after study completion (mostly because ppts with LC will not be entirely known until Y5). Some question of feasibility (no statistical issues). Suggest measuring biomarkers on more than LC only as finances permit.
- Determine if change in biomarkers from Baseline to Year 1 is predictive of LC incidence at year 1.
- Given that only 30 patients have biomarker measurements, limited to only a few predictors in any predictive modeling. Reference penalized logistic regression or L1-lasso modified regression model.
- Some analytical points:
- As a secondary analysis, can use ordinal model for ROC where disease is no longer present/absent, but may be characterized by severity.
- Controls may include severity of dysplasia.
- PM would like to track biomarker over say, 3 timepoints - longitudinal logistic model. Include clinical diagnosis to see if biomarker would lead to shift in clinical diagnosis to have a clinical impact.
- Might plot trajectory of biomarkers and calculate the area under the curve. Then include this AUC as a covariate. This is one solution for a nonlinear trajectory of biomarkers.
- Check out time dependent ROC curves - reference Pepe.
12Oct09
Richard Urbane, Kennedy Center
- Possibly has an overpowered study
- Answer is in the magnitude of the effects
- What are the clinical, social, etc outcomes of your results?
Sara Horst and Christine Crish, Peds GI
- Dataset with two time points
- Abdominal pain in adolescents, one time then followed up five years later
- Symptom scores range from 1-4; and resolved/unresolved score
- Logistic Regression is recommended for dichotomous outcome
- If you break up the resolved group into several categories, should use ordinal regression
Elizabeth Stringer, Imagine Institute
- 2 time courses from 2 parts of the brain
- 3 people measured over 24 seconds, averaged 7 measures
- Fit a model for each individual's time course
- Graph raw data
21Sep09
James Parnell, visiting medical student
- Idiopathic pulmonary fibrosis patients and sleep apnea
- Prevalence of sleep apnea is much higher in this population
- No cure for IPF, studying quality of life with CPAP
- Electronic card records compliance and apnic episodes
- 1) Can they be compliant?
- 2) Do those who are compliant have less decline in lung function than those who aren't?
- 3) Are pulmonary function tests more stable with people who are compliant?
- Small sample size, recommend doing mostly descriptive statistics and graphs
31Aug09
Yogen Dave, Allergy/Immunology
- Study of a drug used with people who have hives
- Used after other drugs don't work; no evidence as to why it's used
- Question about powering a study when there is little preliminary information
- Outcome: score ranging from 0 to 9
- Should use the Wilcoxon Test and/or proportional odds model
- adjust for severity at presentation
- Would want a minimum of 20 patients, preferably 40
31Aug09
Tracy McGregor, Pediatric Genetics
- Idiopathic scoleosis (3% prevalence in general population)
- Controls from an outpatient clinic (some ACS, some not)
- Selected 5 candidate genes - specific SNPs; look at 125 candidate genotypes
- 140 cases, 3:1 controls:case ratio
- Question concern treatment of heterozygous state
- standard chi-square test with 2 d.f.
- group middle group with one of the others (1 d.f.)
- use as ordered (1 d.f.)
- if you can treat the SNP as an ordinal outcome (dependent) variable, can use the proportional odds ordinal logistic model
- The 126 snips can be organized into 5 genes; recommended gene pathway analysis to reduce dimensionality and multiple comparison problems
Jim Gay, General Pediatrics
- Studying quick (15 d) readmissions to VCH
- Preventable readmissions are of major interest
- Two years of data - 1213 readmissions in first year
- 5-level preventability ordinal scale; needs to be validated
- May be of interest to estimate the probabilities of:
- exact agreement
- agreement with regard to definitely preventable vs. not
- agreement within 1 category
- Mainly interested in inter-rater reliability; may also be interested in intra-rater
- For sample size estimate consider estimation of one probability using one proportion, with a margin of error of +/- epsilon
- To estimate the final sample size if there were 3 raters, could get preliminary data on 50 cases and compute the standard error of the proportion of agreement averaged over all pairs of raters
- Do not necessarily have to have every rater rate every subject
- Can use a random number generator to select random records for review
24Aug09
Trent Rosenbloom, DBMI, collaborating with Brad Kheler, Ophthalmology
- Clinical note-writing tools for EMR
- Efficiency tools, e.g. templates, re-using old notes as template for new note with some fields automatically updated with most recent info
- Occasionally internal inconsistencies arise, e.g., one part updated but another part not
- Of interest is rate of inconsistencies vs. type of note/level of physician/specialty
- How many notes need to be reviewed?
- Worst-case analysis: if rate of error is at point of maximum uncertainty (0.5), the sample size needed for the smallest group will need to be N=200 to achieve a margin of error of +/- 0.07 with 0.95 confidence
- For comparing two groups of equal size, the margin of error is 0.1 for estimating the difference in two proportions of errors when the number of cases in each groups is 200; with 400 in each group the margin in error for estimating the difference in proportions is 0.07.
- Focus on estimating the more difficult things; other estimands will be easy
- Beware of the difficulty of estimating relative errors when error rates are low
- Regression models can account for multiple characteristics simultaneously. Outcome could be binary (error/no error) ordinal (to capture severity of error)
- If want to model 5 covariates would need at least 200 + 20*5/Prob(error) = 700 cases if overall Prob(error) = 0.2. This is a target sample size to achieve good predictive accuracy for many covariate combinations. 533 are need of Prob(error) = 0.3.
- Number of covariates is the number of continuous + no. binary + sum of k where k = number of levels of categorical variables less one, for those having 3 or more categories
- 5 category + 3 category + 10 category = 15 parameters to estimate + intercept instead of 5
- Precision of odds ratio when there are N subjects in each of two groups (fold-change or multiplicative margin of error):
- N=640 in each group will allow estimation of an odds ratio to within a factor of 1.25
- May need to audit cases in which neither reviewer found an error
17Aug09
Natasha and Carrie Geisberg, Cardiology
- Studying release of vegf
- Should she consider the location?
Carolina Loria, Infectious Diseases
- Recommend keeping vitamin D levels continuous
- If the outcome is binary, could use Recurrent Event Analysis
- Intensity or Mean Value Function ~ probability of event over time
- To make things simpler, could possibly just look at either the minimum or average Vitamin D levels
- Should set up a model that adjusts for immune response, focuses on infections unique to this population
10Aug09
Natasha and Carolina Loria, Infectious Diseases
- Applied for VICTR money
- Vitamin D deficiency and increase risk of infection
- Measuring Vitamin D at 0 days and 100, should get more?
- Vitamin D is very stable so there is no need to get too many measurements
- If there are multiple measurements, able to show projectory
Charlie Day, Molecular Physiology
- Measuring diffusion of molecules around cell membrane
- Rate at which the protein diffuses around the membrane
- 1 group gets treated, 1 does not
- 20 cells in each group
- Recommend plotting raw data with medians/means and boxplots
- Could use non-parametric statistics - Wilcoxon Rank Sum, Kruskal Wallis
- Regression model: outcome ~ concentration group
- Would recommend bringing data back to clinic
Tao Zhong, Cardiovascular Medicine
- Writing a proposal for a VICTR grant
3Aug09
Dan Barocas and Justin Gregg, Urologic Surgery
- Does pre-op nutritional status effect surgery outcome?
- already has database
- Looked at some variables associated with nutritional status: albumen level, bmi at time of surgery, weight loss prior to surgery?
- Preliminary data to be used to possibly set up a prospective study
- High complication rates (~30%), about 50% survival at 5 years
- Consider using splines for continuous variables in cox models
- Models for survival and for complication rates
Dr Lisa Mendes and Raphael See, Cardiology
- At clinic previous on July 15
- Take the 3 tests, get ROC curves and compare them
- Could set this up as a reader study where several physicians read the same patient outcomes.
27Jul09
Taneya Koonce
- MPH student, studying how education materials affect hypertension at Vanderbilt's ED
- Quiz (12 T/F) given when they are at the ED then again two weeks later
- Expects to see a 10% increase in quiz score
- No data out there currently to give an estimate of the SD
- Frank suggested designing this as a pilot study that gives a narrow CI for the SD to later use to power a study
- See http://biostat.mc.vanderbilt.edu/GenClinicAnalyses#Ken_Monahan_Division_of_Cardiova
- n=50 (25 in each of 2 groups) would yield a multiplicative margin of error in estimating SD of 1.25 in the worst tail
- Would recommend switching order of questions the second time around or changing the title of the questionaire to limit recall bias
David Rho
- Can you compare data between two complex survey analyses?
- Unsure of stratification weights and PSU weights
Carl Frankel, Psychology
- Literature in his field often reports partial-eta-squared from ANOVA for a mixed effects model output in SPSS
- Does not feel as though this is a meaningful statistic to report, what to tell editors?
20Jul09
Laura Ooms, Pathology
- Sequencing of influenza viruses
- Amino acid residue K vs E; interested in replication efficiency
- 1000 viruses are independently studied but using cells from the same organism
- We assume that the 1000 experiments are operating independently
- Can do replicates if needed (2 or 3)
- Need to be careful how cells are placed on an assay plate; also watch out for time trends if experiments are done over a long time span; may need some kind of randomization
- Start with box plots of rep. eff. stratified by residue class; highlights 25th, 50th (median), and 75th percentiles
- Could also make histograms of the two samples
- If the distributions are not normal or the mean is not a good summary measure of central tendency for these data, it would be advisable to use a nonparametric test (Wilcoxon-Mann-Whitney 2-sample test); the parametric counterpart is the unpaired 2-sample t-test
- What to do about other amino acid residues that affect the efficiency?
- To test the meta-hypothesis regarding K vs E, perhaps 200 viruses would be sufficient; the choice of the number of viruses to analyze relates more to the virus spectrum one desires to cover or make inference about in general
- Desire K/E sample size ratio to be somewhat close to 1:1 for maximum power
Robyn Tamboli, Surgery
- Writing a VICTR proposal to get preliminary data for a grant
- Y = insulin sensitivity (difference from saline); will measure before and after bariatric surgery; a continuous measure
- How does Ghrellin affect insulin sensitivity?
- No pilot data available for obese subjects
- Available data provides SD for non-obese subjects
- Literature is deficient in not providing the SD of the within-subject differences (or the correlation coefficients)
- SD of saline result does not seem to be related to the means
- If the correlation between Ghrellin and saline within subject is r, and if the SD on Ghrellin is equal to the SD on saline, then the SD of the differences can be estimated from
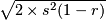
- Assuming r=0 will result in a conservative estimate
- Multiple SDs by the square root of two to get the above
- Can use the PS program to compute a sample size for a one-sample (paired) t-test
- To be conservative again, can assume that correlation between pre-op and post-op is zero
- Conservative pooled estimate of the standard deviation of the double difference: 1.59*2 = 3.18
- If assume that both correlations are 0.5, divide pooled SD of the double difference by 2 to get 1.59
- Might be better to do a precision calculation
01July09
Mario Rojas, Neonatology
- Asked to participate in a randomized control trial comparing SOC to a new treatment
- GEEs are used when data are not all independent
- Change in p-value could be due to confidence interval shrinking. It would be a problem if the added data changed the center of the CI. Think about it clinically.
- 540 singletons, not showing significant differences... added 40 from multiple births, became significant. Would not feel comfortable with end result due to possible bias.
- Would want to see what happens with the 540, then what happens after adding the 40 ignoring correlation, then what happens when you use GEE to account for correlation.
- Should ask for survival curves to see survival over time.
Justin Cates, Surgical Pathology
- Project dealing with a rare tumor, low numbers
- Looking at multiple biomarkers
- Used multiple Fishers Exact tests, didn't see much significance
- Low numbers in cells are okay for Fishers tests
- Could connect tables using logistic regression, need common outcome
- For missing data, could use multiple imputation
- Recommend getting test-based confidence interval from Fishers Exact
- Has some follow-up data for patients, using survival curves
- Proportional Hazards assumptions may not be met
Todd Rice, Pulmonary
- Reviewers told him he needs measure of correlations for five variables
- Bland-Altman Plot: Difference (y) of two readings by the average (x)
- ICC - random effects model - random: cases, reader; want var(cases)/total variance
- want variance to come mostly from cases, not reader
29Jun09
Elizabeth Johnson, Microbiology & Immunology
- 5-8 mice per time point; different animals at different time points (sacrifice times)
- Different organs
- Has done Wilcoxon-Mann-Whitney analysis
- Can treat time as any other baseline variable in this case
- One possibility is multiple regression, allowing for a quadratic time trend in each group; one regression per organ
- 4 genotypes; if analyzed jointly, the group variable below will need to be represented by 3 dummy variables
- Model: y = group + time + time^2 + group*time + group*time^2
- Hypothesis of interest: Are the time trends the same for wild type vs. one of the knockouts?
- Alternative hypothesis: one time trend is shifted up and down from the other, or the time trends have different shape (or both)
- Can carry out using a pooled analysis (for one organ) with specified contrasts
- Hard to know how to adjust for multiple comparisons
- Could test for overall differences and if there is evidence for some difference between some genotypes, can proceed without as much worry
- See DataTransmissionProcedures for tips in preparing data for the clinic. Data can be e-mailed in advance, to mailto:biostat-clinic@list.vanderbilt.edu
22Jun09
S Nair, MMC: Reproductive hormones, gastric bypass surgery, and weight loss
- Plasma hormone concentration levels and phases
- VICTR pre-review raised issue about the power calculation
- Used repeated measures ANOVA ( Note: assumes equal correlations no matter how far apart in time the two measurements are; must adjust final analysis for intra-subject correlation - e.g., Greenhouse-Geisser correction or Huynh-Feldt correction)
- Need number of subjects, differences in means to be detected, alpha level, across-subject standard deviation (at one time), and correlation between two measurements (at different times) in the same subject
- Another comment about analysis model
- Generalized least squares or mixed effects model would be preferred to repeated measures ANOVA
Sunil Halder, MMC: fibroid disease vs. control, vs. vitamin D level
- VICTR pre-review raised some issues
- Not enough information to calculate power
- Need sample size per group, alpha level, across-subject SD of vitamin D level, mean difference (effect size, unstandardized) to detect in vitamin D level (difference one would not want to miss if it exists)
- Review also suggested looking at a binary logistic regression model for predicting the probability of fibroid. If the only predictor is vitamin D level, a linear logistic model is virtually equivalent to a two-sample t-test with equal variance assumption.
- This would be especially pertinent if there were two dependent variables (not just vitamin D); these could be used jointly to predict fibroid, which is similar to a multivariate test for differences in the two markers between fibroid and control. Would require a larger sample size.
- A larger study at the beginning would give more reliable results. Starting a research program with a small pilot study, though the norm, can be problematic.
Note: For both studies, quoting a margin of error for the primary quantity of interest would be more helpful than considering the power
Frank discussed reproducible research policies of Annals of Internal Medicine and Biostatistics
15Jun09
Maria Gillam-Krakauer, VCH
- Designing a study to show that Nirs measurements are associated with the ultrasound measurements
- Want to start with a very homogeneous group to establish that relationship exists.
- Next study use a more diverse population to include more variables such as age, race, sex, etc.
- If possible, get multiple measurements within individuals.
Carl Frankel, Peabody
- Children are placed to overhear an adult conversation with three different tones (angry, happy,?) then told to go narrate a children's book.
- Is emotion before speaking a predictor of whether they will stutter?
- Set up dataset such that each row is an utterance matched with child ID.
- Could use random effects, longitudinal or GEE model.
Max Gunther
- Learning R, suggested using the tutorial from TheresaScott
8Jun09
Patrick Arbogast and Carlos, Preventative Medicine
- Questions concerning how to graph data.
1Jun09
Ken Monahan, Division of Cardiovascular Medicine
- Planning a study of BNP and its variation across heart chambers and peripheral/central circulation
- Will also measure a relative of BNP - NT-Pro-BNP
- How do levels vary with BMI and renal disease severity?
- There is a literature on peripheral variability over time
- If P=peripheral and C=central a useful target estimand is mean |P-C|; estimate the sample size n that will allow estimation of this unknown quantity to within a margin of error m with 0.95 confidence. In other words, for what n are the expected confidence limits +/- m from the mean absolute difference? An observed mean absolute difference might be 40; we would want a margin of error say 25. Alternatively (especially if BNP has a log-normal distribution) you can specify the multiplicative margin of error (fold-change moe). This might be for example 1.1.
- For absolute moe we need an estimate of the SD of |P-C|. For relative moe we need SD of |log(P/C)|.
- Sample size formulas are in https://data.vanderbilt.edu/biosproj/CI2/handouts.pdf p. 49
- First need to make Bland-Altman plots to show that differences are independent on base levels (either on original or log scale)
- Plots of differences (y-axis) vs. average (x-axis); log ratio vs. mean of logs for relative assessment
- Basis for taking logs or not; need to do this before proceeding with sample size calculation
- Need a justification of sample size for the pilot study
- Need to consider multiplicative margin of error for estimating a standard deviation
- If n=5, the multiplicative moe is a factor of 0.6 to a factor of 2.87
- Would have to take an SD estimate from the pilot study with a grain of salt (i.e., multiply it by 2.87)
- Would need n=25 to get multiplicative moe < 1.39
- A paper by Helena Kraemer discusses pitfalls of pilot studies
- For group comparisons, it may still envision as an moe problem; goal is to achieve a certain moe in estimating the difference in two means (between two groups); see p. 56 of above handouts.pdf
- Need an estimate of the SD of one type of BNP across patients (or of log BNP if that transformation is warranted)
18May09
Jon Tapp, Kennedy Center
- Mass spec data needs to be normalized to each other in order to be summarized and compared. Methods for doing this were breifly discussed.
- http://www.vicc.org/biostatistics/software.php may be a good place to start a literature review for specific techniques for doing this. R and Matlab libraries might be a good resource as well. Perhaps try a Tuesday genomics clinic. Email to yu.shyr@vanderbilt.edu might be of use.
Casey Coke,
- Casey has visited previously. She is investigating the incidence of cage floods pre and post training. Floods are caused by mice, or by the mechanism, or are unknown. Census is conductd every 2 weeks over 2, 6 month periods.
- The question of interest is, has training effected the number of floods?
- Try and get rid of as many unknowns as possible.
- First, test to see if overall number of floods has increased using either confidence intervals for the proportion or using the total number of cages in a logistic regression. If actual count for total cages can't be ascertained, grouped logistic regression is a good option.
- Second, create a 2 by 3 three table of time period and flooding cause and use a chi-squared test to see if proportions of the cage flooding cause is the same pre and post training.
- Bring data to Monday, Wednesday or Friday clinic for analysis in an excel spreadsheet.
Chad Boomershine, Medicine
- Comparing a full length questionairre (gold standard) to a visual assessment analog. The visual analog does not have a gold standard for all the measures. For these measures without a gold standard, can historical measures be used to make cut-off. For example, if the literature indicates 75% are known to have fatigue, can the cut-off be made at the 75 percentile?
- This is a reasonable idea, but may require some justification.
- There is a second group that the cut-off may be tested in. Bootstrapping might also be useful in determining cutpoint. QQ plots might also be useful.
- If data isbrought back, smooth ROC curves can be made in STATA. Data should have three columns, one for positive or negative, one for study group, and one visual analog score.
Phill Gorrendo, Neuroscience
- Parent report has been used to associate a particular allele with a GI problem in autism.
- Sample size for prospective study with three groups of people. One group is GI problems but no autism, another autism w/o GI problems, and the last is autism w/GI problems. Wants to answer if allele 1 is common in the autism and GI group compared to the autism only group.
- Previous study indicates 65% of group with autism and GI problems have allele 1 and 48% of general population have allel 1.
11May09
Masud Reza, Institute of Global Health
- Incidence of hepatitis C and other diseases over multiple visits of IV drug users in Dhaka, Bangladesh
- Recommended reliance of usual life table or Kaplan-Meier estimates instead of person-years method
- Some analyses of interest are visit-wise incidence over time for which a full likelihood (e.g., random effects) models
- Possibility of informative censoring is a potential problem and should be listed as a limitation; assuming censoring (loss to follow-up) is independent of impending risk of event
04May09
Shanti Pepper, Psychological Counseling Center
- Theory of Self-Efficacy study, belief in your ability to accomplish a task or a goal.
- Developing a scale based on the four sources and a scale
- 17 items, 415 subjects
- Structural Equation Modelling with EQS, recommended book
- Purpose of confirmatory analysis: to confirm that her theory fits the data
- One particular item is preventing the model from fitting
27Apr09
Xiaoli Chen, Epidemiology Center
- Baseline = 6m post breast ca dx; measured physical activity (PA, mets) and QOL (0-100); N=2000
- 18m post dx: measured PA
- 36m post dx: measured PA and QOL
- Question: how does PA after br ca dx improve QOL?
- Does treatment need to be factored in? 90% rec'd chemo within 6m of dx
- One model to propose: QOL(36m) = QOL(6m) + PA(6m) + PA(18m) + other 6m variables
- Ordinary regression model (all fixed effects)
- Chunk test (composite test) of joint effect of PA(6m)+PA(18m) (2 degrees of freedom)
- 2 approaches: make a 2 d.f. contrast (SAS PROC REG has a TEST statement; i.e. TEST PA6, PA18;) or remove both PA variables and do the "difference in
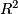 " 2 d.f. F-test
" 2 d.f. F-test
- Chunk test more meaningful than individual partial tests of two PAs if they collinearity
- Answers the question of whether PA is influential on QOL after adjusting for baseline QOL
- Not predicting QOL(36m) from PA(36m) because of a circularity problem in the causal chain
- It will be of interest, after examining the two PA regression coefficients, of see whether it is the simple average of the two PAs that predicts QOL
- PA enters the independent variables as a baseline variable and an updated baseline variable.
- May want to examine an interaction between disease stage and (first) baseline PA and baseline QOL
- Separate analysis (correlational) QOL(36m) vs. PA(36m)
- Another analysis to show would be the relationship between the two later PA measurements.
- Cohort is women who survived 6m after ca dx and who had PA and QOL measured at that time.
- Answer to reviewer: Because of the nature of the data collection, QOL is only measured at one time post baseline. Hence the analysis of QOL is not a mixed model problem but is an ordinary regression problem. PA at 6m and 18m serve as two simple baseline measurements in this simple regression model. The mixed effects model would be a good model had PA been the main dependent variable of interest. If desired you could mention that this problem was brought to the Department of Biostatistics daily clinic and this was the advice given by the 8 biostatisticians present.
Yuwei Zhu (Biostat)
- Question on excess rate
- A difference in two rates is not a rate
- Rates are quantities that are used in ratios, not in differences
- Try to think about a ratio of ratios (or double difference of log rates)
- Variance of log ratio of ratios is a simple sum of 4 terms cases like yours
13Apr09
Carl Frankel, Peabody Psychology
- Continued question from Friday about shrinkage
6Apr09
John Schmidt & Jessica Holland, NICU
- Arterial blood gas: transcutaneous continuous CO2 monitor
- Need to look at safety in neonates (previous studies only down to 2y)
- Babies who were ventilated and had indwelling arterial line and > 1Kg
- Took picture of skin immediately after removal and up to 36h later
- 15 patients; 1 had only 2 readings before art line came out; 1 had 21; avg. 5-6/pt
- sick children q1h; less sick q4h
- Bland-Altman technique is of interest, but need to handle multiple readings per patient
- Doing the plot on all raw measurements is still meaningful
- Plot appears to be consistent with analysis on the original scale
- One approach is to compute the average absolute difference at each time point and then to average that over all the time points within baby
- Show histogram of 15 absolute differences
- Compute average of 15 mean absolute discrepencies and get a confidence interval for that (bootstrap will work best); confidence interval will be asymmetric
- Compute overall mean of signed differences, just to look for a systematic difference (i.e., drift)
- A formal modeling approach (generalized least squares or mixed effects models) could better take the correlation structure into account and result in more efficient estimates, if model assumptions are satisfied
- Also make spaghetti plot of all trends in all babies. Time is on x-axis; two curves per baby.
30Mar09
Josh Tardy (Resident) and Buddy Creech, Pediatric Infectious Diseases
- More infections in ED requiring drainage; adults & children
- Interested in spikes in 3 months; one strain of staph aureous
- How to check statistical evidence for seasonal trends
- Can use time series analysis; model a long-term trend and a seasonal trend
- A model could have terms for each calendar month plus a long-term linear trend (have 5y of data)
- Can analyze as weekly or monthly rates; may need to time with return to school for kids
- Could test for different trends for adults and children
- One model: f(year + fraction of year) + g(fraction of year) + h(age), f= spline with 3 knots, g=spline with 10 knots
- fraction of year starts over at 0 at next year
- may want to interact h with g
- Poisson in counts with offset equal to the number of ED
Michael Hebert, Peabody - Special Ed
- Essay writing quality scores; N=137 kids, 4 essays/kid (order randomization unknown at present)
- Each essay was scored by two raters; were probably averaged; might look into possible information gain from using both ratings instead of averaging
- Want to see if predictors predict differently for different tasks
- Interaction test between all predictors and genre
- Hierarchical mixed model: students, 4 genre (looking at one at a time, e.g. essay writing)
- If only one level of clustering, could also easily do this with generalized least squares which also makes for easy allowance of heteroscedasticity
- Heteroscedasticity present according to White's test
- Need to look for systematic changes in spread, e.g. box plot stratified by three variables (e.g., gender by tertiles of age by genre); also do scatterplots
Amanda Wake, VUIIS, biomedical engineer
- Will write a grant to start a study on Ped sickle cell anemia (7-15y)
- One pop. at risk for stroke because of arterial velocities (time averaged mean, cutoff of 200; requires looking a multiple arterials), one not
- Flow rates, wall shear stress, bifurcation angles; MRI currently being used only for qualitative assessments
- N=16 vs. 140; generally too many patients are put on transfusion regimen because of stroke risk
- Need to adjust for time avg.
- Might plan as correlation analysis moreso than 2-group comparison
- https://data.vanderbilt.edu/biosproj/CI2/handouts.pdf has a graph showing how to estimate the sample size needed to estimate a correlation coefficient with a given precision
Nikki Davis, behavioral neuroscience in Peabody and VUIIS
- Grant for June; N=60
- Children varying in response to intervention; what are functional differences?
- Need to do pre- and post-scan; parallel group design with pre- and post- measurements; suggest adjusting for pre measurements using analysis of covariance; may be need worry about interaction between pre and group
- interactions will have low power
- Response to intervention: curriculum-based measure - word indentification and fluency test; battery at week 6
- Subjects will enter the study at 6w; want to sample from a spectrum of risk of responding; no tier 3
- Y= continuous or ordinal; use measures used to determine groups, not responder/non-responder groups themselves
- May be worth getting an enriched sample with extremely high or extremely low scores if can get adequate sample size in both and the two groups are someone homogeneous
- Meet with Lei Xu
Carl Frankel, Psychology
- Question on modeling time effect in a longitudinal data analysis
6Feb06
Alan Storrow and Karen Miller (Emergency Med): Digital Stethoscope
- Expertise of clinicians in study
- Randomize when possible, watch for learning curve especially for younger clinicians; adjust for order effects in final analysis
- Possible to use many physicians but only 3 for any one patient
- Grade levels of positivity when possible
- Interobserver variability (disagreement)
- Test-retest reliability of new device
- Absence of true gold standard
- Is there a realistic simulator that can serve as a gold standard?
- Will detection of more heart sounds lead to overdiagnosis / overtreatment or will it identify patients at higher risk in a way that is still clinically useful?
- Device outputs a sound find that might be further quantified; also outputs abnormal S3
Baxter Rogers (VUIIS): fMRI Brain
- Finding location in brain where there are signals when math problems being solved, then look at differential math problems
- 10-20 subjects each doing 4 math problems
- One cell in 20x4 table may be a time series from one pixel, averaged over several activations. There are baseline levels when the math problem is not being done
- Done over 10,000 pixels
- Randomized order of math problems; within a problem there are runs over time with alternating 40s control periods; data use differences
- An analysis with a multiplicity adjustment that ignores the spatial correlation between pixels will be conservative
- Test for existence of any signal; Wilcoxon signed rank test can be used to test for a signal for one math problem (e.g., A) (analog of paired t-test); to handle 4 simultaneously need a multivariate test or an adjustment for cluster sampling; a nonparametric cluster method may not have enough power unless there were more subjects
- A more comprehensive mixed effects model could use original data, not differences from control. This model can solve the one-sample (Wilcoxon sign-rank type) problem also, since it can provide a contrast with control
- R functions to look at include lme() and nlme()
- 27Mar06
Jon Buzzell (Orthopaedics)
- Test pin distance into bone across plates and samples
- arrange data into right order, e.g, the higher the worse
- Kruskal-Wallis tests.
- Will send in data and we'll do the tests
- Analysis was done and result was sent on Feb 07. Cindy performed Kruskal-Wallis test to compare the pin distance into the bone as well as percentage contact of the bone with the plate across plates and arms. Mean and standard deviation were also given for each plate and arm.
13Feb06
Martincic Danko (Medicine): revisit
- study the relationship between TGIF real time PCR and TGIF hybridization
- original paper used Kappa test with dichotomized points depending on the data, which is not valid
- PCR = log10(TGIF/HouseKeeping), Hybrid=log2(ref DNA/TGIF)
- fit linear regression model to 1/2^Hybrid with 10^PCR, test slope, check residual
- Calculate Pearsons coefficient and its confidence interval
- areg.boot() in Hmisc
Alan Storrow and Karen Miller (Emergency Med):
- Evaluate effect point-of-care has on various efficiency measures
- specificaims.doc: Specific Aims
- randomized design is difficult in this study; many measures are for the system not indivudual patient; the intervention would have occur all patients at once.
- Pre and post intervention test
- Other comparable ED information can be used to control for seasonal effect
21Feb06
Karen Miller (Emergency Med):
- we taught her sample size calculation
- she taught us scientific knowledge on vaccine
27Feb06
Clint Carroll, 2nd year medical student advised by Jim Whitlock MD
- https://biostat.app.vumc.org/wiki/pub/Main/GenClinicAnalysisArchive/clintCarrollabstract.sxw Abstract | https://biostat.app.vumc.org/wiki/pub/Main/GenClinicAnalysisArchive/clintCarroll.sxc Data
Stephen Henry, medical student
- 5-level ordinal variables; mean may be useful summary along with proportions
- variable clustering will be a nice descriptive tool
Patrick Burnett, Dermatology
- Photographs of lesions vs. pathology; malignant vs. benign
- Previous data 38 observers on 20 lesions
- Some lesions are read more than once by same observer
- Most interested in 0-7 grading
3Apr06 Heather Burks
# Wilcoxon Signed-Rank Test del <- as.numeric(b$delta.GAF) wilcox.test(del, rep(0,length(del)), paired=TRUE) #P=0.068 t.test(del, rep(0,length(del)), paired=TRUE) #P=0.056
# Parametric 0.95 confidence interval (-14.4, 0.21) # Nonparametric bootstrap 0.95 confidence interval: smean.cl.boot(del, B=10000) # (-13.3, -1.3)10Apr06
Jin Jan, Keith Wrenn, Emergency Medicine
Question: What are the factors other than working hours affecting physician stress in ED?- 18 physicians were enrolled
- standard stress survey (20 questions, 4-point for each question) was given to each physician after 4 morning, 4 afternoon, and 4 evening shifts, so totally 12 stress score measurements for each subject
- Covariates: bad outcome, bad interaction, load(?)
- compare scores among morning, afternoon, and evening shifts using Kruskal-Wallis test
- Repeated ANOVA
- random effect model
Mary Alice Nading, VUSM(II)
- Box-plot
- Wilcoxon rank sum test to compare pregnant vs non-pregnant woman
- ANOVA
17Apr06
Daniel Foretis, Clin Pharm MS
- Wilcoxon signed rank test of correlation coefficents for dose reponse within organ
- Two sample Wilcoxon sum rank test for AUC across drugs
10Jul06
Paul Mathieu, first year medical student under the direction of Mac Buchowski, Nutrition Center
- 12w weight loss/body composition randomized study of dietary calcium; all subjects are on a high calcium diet
- started with 40 subjects
- 6 subjects dropped out
- dairy N=16, non-dairy N=18 completed 12w
- analysis must have N=40 as denominator to be valid unless dropouts were VERY early, or do worst-case sensitivity analysis
- 3 dropouts in dairy, 3 in non-dairy
- Need to look up dropout times for these 6 subjects
- Outcomes: weight, water, lean mass, body fat, bone mineral density
- Baseline covariates: race, age, height, calorie intake, weight, labs
- A goal of the analysis should be the comparison on 12w responses between the two groups, not discarding any subject who had at least one follow-up visit, whether or not they dropped out before 12w. Analysis should use all available weeks, but target the estimation and hypothesis testing at the 12w response.
- Analysis of weight change within subject is not of interest in a parallel-group study, although baseline weight might be adjusted for in analysis of covariance
- Model:
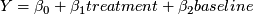 , Y=response variable
, Y=response variable
- But model has to have time in it because there are repeated measurements
- Model:
- Plotting raw data is a good idea
- scatterplots
- spaghetti plots (trends for all subjects, connecting points measured on the same subject, time or visit is on the x-axis); make dropout times obvious, make separate panels by treatment or other variables
- box plots emphasizing 25th, 50th, 75th percentiles; a good way to summarize a group such as 12w bone density males vs. females
17Jul06
Katrina Gordon, First year medical student
- Suggested having SPSS compute aggregate statistics by subject ID and year within subject compute the mean activity level
- Will need to program carrying ID numbers forward when left blank; in R this can be done by
- Zeros in data need to be changed to blanks
- Make spaghetti plots of these means over years by subject
- Make box plots
24Jul06
John Starkman, Urology
- Designing clinical trial female urinary incontinence
- 2 types of anesthetic, 4 groups
- VAS to measure patient's impression of pain
- Need standard deviation ( not standard error) of a group of patients' assessments, with patients being treated in a way that is not unlike the procedure of interest, or at least patients having the same disease and disease severity
- Need difference of clinical interest - absolute difference of mean VAS between groups to be able to detect or an acceptable margin of error in estimating the difference in two means
- Need to measure VAS with high resolution to minimize the number of tied data values in the analysis
- Consider whether a formal 2x2 factorial analysis would give more information / more power by pooling some treatment arms when testing others
- Could add another factor (2x2x2) prophylactic antibiotic
- Use blocked randomization to keep the design balanced as the study progresses
31Jul06
Andre Diedrich - Clin Pharm
- True multivariable problem; we are not sure if Friedman's test is appropriate. At least, Friedman's test cannot make use of the ordering of the different conditions under which the patients are studied. Wilcoxon signed-rank tests done on pairs of conditions cannot show significance after adjustment for multiple comparisons with N=7.
- If you can order the conditions under which the patients are studied, you can compute the Spearman
 rank correlation between the ordered condition and the response variable. Get 7 Spearman correlations, test for being significantly different from zero using the t-test.
rank correlation between the ordered condition and the response variable. Get 7 Spearman correlations, test for being significantly different from zero using the t-test.
- If all 7 correlations have the same sign (and no zeros), P-value is exactly
 by the Wilcoxon signed-rank test, and the t-test is not needed
by the Wilcoxon signed-rank test, and the t-test is not needed
- Require apriori hypothesized ordering of conditions, blinded to the actual data
- Reduced multivariate data to one number per patient (correlation coefficient)
- Assumptions
- monotonic relationship between hypothesized ordering and the response
- Spearman values are approximately normally distributed
- Could have summarized each patient with a slope if linearity held (and no problem with overly influential observations)
16Oct06
Bahram Khazai, VA Internal Medicine
- Interested in comparing type I diabetics and controls on serum IL-4 and gamma
- Groups were matched on sex and mean age
- Plotting raw data: dot plots (with a line showing the median), box plot, scatterplot with age on x-axis, scatterplot with box plots for each axis showing one-way (marginal) distribution of the response variable
- Test for whether measurements in one group tend to be larger than measurements in the other group: Wilcoxon-Mann-Whitney two-sample rank test (for unpaired data)
- Does not assume normality or equal variance
- Values below the lower limit of detectibility can be set to any value that is lower than any real value
- Be careful when excluding observations; must be done objectively and in a way that is blinded to case/control status. Need to check cases again to give them the same chance of having observations excluded as was given to the controls. Generally don't exclude data that are not illegal (and rank tests are not overly influenced by extreme values).
- Can use a logistic regression model to predict group from IL-4 and gamma simultaneously, to get a multivariate test on whether either IL-4 or gamma differs by group
- Look for more complex relationships, e.g.., group difference expands in proportion to age or BMI
23 Oct 2005
Abigail Brown, Mol Physiology Biophysics and BRET
- Problem with normalizing experimental brain sections to control by dividing; assumes that control rat brain measurements have no error and no biologic variability
- Normalization should be part of the analysis; it should only be done separately when the normalizing parameter is a constant measured without error; however it may be beneficial to plot the paired differences.
- Dynamite plots are hiding the raw data; sample sizes are small so show all data - see DynamitePlots
- Could do two Wilcoxon signed-rank tests each comparing with basal (unnormalized). Note that in some of the pairs a mate was lost.
- Adjustment for multiple (2) comparisons probably not needed
- But there are 6-7 hypotheses related to different possible pathways; beware of higher chance for spurious findings. If all tests are reported and you don't just report the significant ones, there is less need for multiplicity adjustment
- An issue was raised about the power of the comparisons that were "insignificant" when the sample sizes are small. Power analysis would show what we already know and would assume that the observed standard deviations are accurate. Could compute ordinary confidence limits for difference in means from paired t-test. Quadrupling the sample size will halve the width of the confidence interval.
- Need to show scatterplot with basal values on x-axis. Also consider Bland-Altman plot which is difference vs. average (of basal and the other group being examined); B-A plot should be flat if subtraction is the correct way to measure the effect.
Jodi Weinstein SOM
13 Nov 2006
Libby Stone, Clin Pharm
- General question about P-values - see ClinStat for more background information
- P<0.05 cutoff is arbitrary
- P-value and test statistic gauge the extent to which the data embarrass the null hypothesis
- Large P-value means more data needed, nothing more
Ellika Bartlett, Med Student
- Survey in Peru: HIV and syphilis prevalence
- Identified persons who had easy access to clinic
- 3 week snapshot, one day in each community
- n=280; prevalence low for both
- http://statpages.org/confint.html#Binomial can be used for computing confidence intervals for true incidences (note that exact confidence intervals are conservatively large)
- A dot plot of age of first sex stratified by presence/absence of disease would be useful - see DynamitePlots and SPSS can make these
27 Nov 2006
Edward Butterworth, VUIIS
- 2x2 setup: lying/sitting, eyes open/closed; sex evenly distributed (but if sex affects response there may be a power gain from adjusting for sex even if balanced); 19 subjects, same subjects in each of the 4 cells
- Look at excess of brain alpha wave production using log ratios; higher peaks when eyes open
- Need to verify that log is the correct scale using for example Bland-Altman plots (scatterplot with y=difference in logs, x=average of logs; plot should be random scatter with no trend, equal variability across x)
- Could analyze as a multivariate (4-variate) response
- If there are no covariates, this can reduce to a series of paired tests (e.g. Wilcoxon signed-rank test but assumes no important variation explained by sex and age)
- There are 3 unique differences so could adjust for multiplicity by multiplying P-values by 3 even though perhaps 6 P-values are computed
- Another approach is to use a two-way ANOVA adjusting for intra-subject correlation using the cluster sandwich covariance estimator (GEE using working independence assumption) or cluster bootstrap
- Mixed-effects model would be preferable if there is evidence for subject-specific mean levels, but its assumptions are unverifiable for small numbers of subjects
- LOA_condensed_data.sxc: Data from Edward Butterworth
12Feb07
Megan Strother, Vanessa Wear, Radiology
- Accuracy of CT scan for recurrent parathyroid adenoma, arterial vs. venous phase
- Surgical planning
- Tumor vascularization
- Morphology
- Delineation from surrounding tissue
- Two independent viewers review both phase scans
- Need to rule out the need for both A & V
- Gold standard: surgery, scintigraphy, path report; all have had surgery
- Could estimate Prob[at least one of A V - | adenoma present] = Prob[one phase is inadequate]; can be estimated with no gold standard
- Need to randomize order in which scans are read
- With 9 patients if there were no disagreements, the upper 0.95 confidence interval still exceeds 0.3 for a probability estimate (3/N rule)
- For multiple readers can compute a summary measure over all possible pairs of readers
Fern FitzHenry, Biomedical Informatics
- Charge comparison before and after an intervention, 30d follow-up
- All outpatient clinics on campus, intervention by groups, difference dates, groups by complexity
- Consecutive patients
- CPT code billing
- Errors in data
-
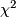 test for proportion of charges with a technical charge pre and post intervention
test for proportion of charges with a technical charge pre and post intervention
- Assuming independence of observations
- Can attempt to show time trends by groups and mark points at which interventions were made
20 Aug 07
Jason Castellanos, Medical Student
- Relationship of secondary cancers to smoking history, for patients undergoing prostatectomy
- Important to get date of birth or age added to dataset
7 Jan 2008
John Scott, MS II, advisor: Dr Buschell
- Vocal cord paralysis from PDA surgery
- 4 surgeons, one has high rate
- # cases ranges from 19-57
- Birth weight, weight at time of surgery, age, other factors likely important
- Significant association between surgeon and Prob(VCP)
- Confidence intervals for all surgeons are wide
- Only 9 events total; noted 15:1 rule
- Could fit a propensity score type of binary logistic regression model to predict cases going to the high surgeon; this will expose case mix differences; subject matter expertise can be used to interpret the tendencies to go to that surgeon to see if she/he was at a disadvantage
- Having an accepted acuity score or severity of PDA would help
- Covered 3/n rule: upper 0.95 confidence interval if there are no events is approximately 3/n
11Feb08
Kathy Hartmann, OB/GYN
- No randomized trials on benefits of uterine fibroid excision
- Are certain types/locations of fibroids more harmful esp. with respect to miscarriage?
- Project has looked at various risk factors for fibroid growth esp. environmental
- Ultrasound week 6-7 of pregnancy; blinded reading; threshold 0.5cm, triggers invitation to cohort (case); device standardized
- Random sample of 100 matched controls (age +- 5y, coming to sonography); 88 completed so far; come back at 15w, then dropped if no fibroid
- 300 cases
- Completed 280 ultrasounds; 1st trimester, 15w, 27w, postpartum
- Avg. of 3 maximum diameters; validation against 3d ultrasound
- Nonrandom missingness as uterus grows, and at later time a fibroid may appear at a different location and disappear from the previous one. Did it move? Identification problem is present.
- 5 categories of fibroid related to wall span. Classification can change meaning as uterus grows and its wall thins.
- How to deal with multiplicity and severities of lesions?
- Could clusters of trajectories be formed, then related to outcome?
- Initial goal is to demonstrate a safety signal or lack thereof.
- May need to take into account that a disappearance of one lesion and a doubling of another may be worse for the patient than stability in both lesions.
- An ordinal hierarchical scale may be worth examining. But clinical knowledge base is suspect.
- Consider training/test sample split.
17Nov08
Jill Simmons, Pediatric Endocrinology
- Bone density in pediatric diabetes
- Issue is not having raw data or standard deviations but being given percentiles and need to convert to z-scores for IGF-1.
- Could convert everything to percentiles. Beware of assumptions made in original z-score derivation. May be able to use linear interpolation to estimate percentiles, and then could solve for z-scores that correspond to these percentiles.
- Ayumi Shintani can help as part of the diabetes training center.
Zac Cox, Pharmacy
- Antibiotics dosed on patient weight, looking at renal function
- Look retrospectively at doses and frequencies, group patients as inside or outside a window, look at proportions of the optimal doses
- Jeffrey Blume had previously suggested that differences (or ratios) from optimal dose might give a better analysis, instead of grouping patients
- Consider interrupted time series approach
- If cancellation of too-low and too-high doses is not appropriate, compute the mean absolute value of the difference between the dose used and the target dose. This becomes an estimation problem, not a testing problem. The bootstrap could be used to get a nonparametric confidence interval.
- Preliminary assessment is underway. Could be used to estimate the needed sample size. For those patients for whom the tool is not being used (15%?) Zac is running the patient characteristics through the tool to get the target.
- Need for formally analyze whether discrepencies with the tool's optimal value behave on a difference scale vs. a ratio scale. A Bland-Altman plot can be used, e.g., plotting difference vs. mean of two doses, and plotting the % difference or log ratio vs. the geometric mean of the target and used dose.
Ayumi Shintani, Biostatistics for Nephrology
- Protocol modifications after DSMB report re: baseline imbalance (49% vs 65% on one Hx variable)
- Choices: biased-coin randomization (requires complex P-value calculations), blocked randomization
- Possible simple one-time bias computation: estimate allocation ratio for positive Hx vs. negative Hx as of current data, and bias all future randomization to give the correct expected correction
- Remember Stephen Senn's advice: the approach to modeling dictates the randomization/study design, not vice-versa
1Dec08
Darby Siler, Pharmacy
- Blood, sputum, or urine cultures on 10-20 or so patients for each organism in each time period
- Gram - organisms isolated in last 3 months of 2007, 2008
- Each organism tested against multiple antibiotics to get % susceptible
- Interested in contrasting the two years
- Petri dish grows organisms, dish has multiple spots for exposure to different antibiotics
- % susceptible is a % of patients
- Assume worst case of 50% susc., a sample of 100 patients with an organism would result in a margin of error of +- 10% susc.
- Basic analysis is a comparison of two uncorrelated proportions (assuming no patients appeared in both years) with a 0.95 confidence interval for the difference in two proportions
- Do this separately for each organism and antibiotic combination (88 differences unless less common organisms are omitted)
- May be interesting to assess the impact of the number of days since the start of the rotation of a new preferred antibiotic within a unit
8Dec08
Julie Wright, Nephrology
- Questionnaire on awareness of chronic kidney disease
- Linked with a health literacy project
- Some issues: should questions should be leading? How do you best all responses that may indicate the breadth of ignorance about the subject?
- Make more choices (e.g., 5 instead of 3) for questions about the amount of knowledge the patient has in specific areas.
- Is there value in first asking a question about what are kidney programs, before asking about the patient's problem.
Catherine O'Neal and Tom Talbot, Division of Infectious Diseases
- Sternal wound infections
- Controls from both the outbreak year and the year before
- One case did not have 2 controls, one case had no controls
- Issues was the low number of matched sets that were informative
5Jan09
Ryan Moran, Pediatric Critical Care Fellow, MPH program
- Pediatric critical care transportation in Costa Rica, mortality & morbidity
- Death is primary response variable
- Data collection starts with ED
- Start is at regional hospitals; all pts are transported to a central critical care specialty hospital
- Problem collecting data on patients dying during transport
- Denominator is all pts transported to the hospital requiring critical care
- Region of origin may be a major factor
- Interested in IV placement and intubation during transport
- Expect to collect 1-2y of data (250-300 pts/y)
- biost_clinic_stephanie_vaughn.xls:
- biost_clinic_stephanie_vaughn.csv:
- biost_clinic_stephanie_vaughn.dta: Stata datafile for Stephanie Vaughn
- biost_clinic_stephanie_vaughn.log: Analysis results for Stephanie Vaughn from April 30th clinic
12Jan09
Bart Mast, Biomedical Engineering, student
- discussed SMLR models
Elvin Woodruff, Biological Sciences
- Interested in finding a method to describe the difference between two distributions of similar density of vesicles in images.
- Overall density is similar but distribution amongst image is not.
- Frank suggested generating an ellipse capturing 90% of vesicles then comparing two parameters: distance from center to active zone and the ellipse's longest diameter.
- Either use multivariate approach or two univariate comparisons.
- Frank also suggested calculating average distance of each vesicle from the active zone.
- Use the computer language C or Fortran to program
19Jan09
Ryan Hollenbeck and Julie Damp, Cardiology
- discussed pre/post assessment of learning intervention data
- Data to be re-structured and re-submitted for later clinic
- Note: Pre and post measurements on different subjects (not paired data)
02Feb09
Andrea Hillock and Al Powers, Neuroscience
- Longitudinal study, binary outcome
- Use GEE (Generalized Estimating Equations), not ANOVA
- Using SPSS, suggested finding another program to use GEE
- Could reduce data to one number such as inter-quartile range then use Wilcoxon Test, or paired t-test for before and after training
- Suggested a collaboration plan
- Jose Mora has suggestion for using GEE in SPSS
Jose Mora and Elizabeth Heitman, MSCI
- Studying an area outside US, low number of diseased cases (10)
- How do you start a study on such a small number of patients?
16Feb09
Carl Frankel, Psychology
23Feb09
Charlie Wright, ENT Resident
- Studying otolaryngitis patients, 2 groups - Need surgery?
- Retrospective chart review, what are the factors going into having surgery?
- 108 patients, 4 did have surgery
- Need between 10-20 cases for each factor you're looking for
- Could do subset analyses of just 104 people who did not have surgery
- csi 4 2 0 80, exact
- Recommended coming to clinic on Wednesday or Friday as well.
Chris Peryan, Pharmacist
- Waiting time for an antibiotic
- Has skewed data, previous clinic recommended taking logarithmic transformation
- Three recommendations: 1) Do t-test on logarithms, 2) Do t-test on the skewed data, 3) Do Wilcoxon Rank-Sum test on skewed data. All three should give roughly the same answer.
- Wilcoxon Rank sum is a non-parametric test, meaning that there is not an underlying assumption of Normality. This test does not give point estimates though.
- Get a confidence interval on the logarithmic data then exponentiate each side.
- Recommended Stata commands: summarize; ranksum x1 x2; ttest x1 x2, unequal
- Could bring back in raw data to another clinic.
- Use "gladder" function in Stata to see different transformations of your data to see how that affects skewedness.
Sasha Key, Kennedy Center
- Sleep study - 35 kids total with sleep apnea
- Degree of severity can be picked up by brain measurements (EG)?
- Measurements can be anything from -inf to +inf
- Sleep apnea index numbers included as well - two numbers
- Do regression with everything that you think is important (2 severity indices, gender, age) - key main effects model. Include interaction term for the severity indices.
- Using SPSS, make sure it knows that categorical variables are categorical or code them as 0's and 1's.
- Age probably won't be linear, try using splines or squared and cubed terms.
- Run that model and report it.
- Stata: robust regression (rreg)
16Mar2009
Rejoice Opara, VMS I
- Doing emphasis project abroad at Costa Rica's National Children's Hospital
- Studying Meconium Aspiration Syndrome
- Cohort: children with syndrome, unknown size - probably in the hundreds
- Characteristics unique to this population compared to other inference?
- Mentor said there will be no control group
- Determine risk of developing MAS - Need estimate of group Meconium-stained amniotic fluid and of that group, number with MAS
- Freq of referral to Nat'l Children's Hospital and where they're coming from - look for characteristics that may possibly be unique for each hospital
- Morbidity rates, etc.
- Physician Survey - do they have the resources for an emergency c-section? if not, what's the standard protocol? what geographic area are these doctors practicing in?
- How detailed are the death certificates? Would they specifically say the child died of MAS?
Roger Taylor, Psychology
- Learning and Emotion Questionaire, teachers vs non-teachers
- Only has 15 in each group - how to present the data and do statistical tests?
- Two outcomes being measured
- If comparing one outcome, could do a Wilxon Rank Sum test
23Mar2009
Susan Beli, Fellow Cardiovascular Medicine
- Renolizine study of diastolic dysfunction
- 2-period 2-treatment crossover study; 5 day washout
- Continuous response variable
- Could randomize about 30 patients
- If somewhat confident about the washout, can use a Wilcoxon signed-rank paired test to test for B-A (pooling B-A when A was first with B-A when B was first)
- Original baseline measurement is ignored; can take full advantage of the crossover design
- Secondary analysis for the existence of a carryover effect, e.g, two-sample Wilcoxon-Mann-Whitney rank-sum test of B-A when A was first vs. B-A when B was first; if the results of the carryover test are used to change the primary treatment analysis, this will greatly distort the type I error (P-value) from that overall treatment effect analysis
- Need to find out the relative power of mixed effects models vs. simple paired tests
Tom Campion, DBMI
- Nurses administering intensive insulin therapy for tight control of blood glucose (80-100)
- Opportunity for keying errors when ordering the dose
- What is effect of overrides; are nurses' overrides clinically appropriate?
- 9000 patients over 5 years
- Comparing reading from glucometer with manually entered blood glucose reading from nurse
- Machines are identical across the hospital
- Dose values before and after override are known
- For error analysis
- Compute the proportion of disagreement, mean absolute error, mean absolute error when there is an error
- Compute the mean and median signed differences to look for errors that are systematically high or low
- Show high-resolution histogram of absolute differences
- Do a Bland-Altman plot to check for any relationship between the base level and the magnitude of the error (plot of difference of two readings vs. average of two readings)
- More in-depth analysis could be based on a mixed effects model with nurse and patient effects; a patient can have many measurements
- Could relate sum of all absolute errors within patient to hospital death or hospital length of stay post glucose measurement
Farhaan Ahmad, Fellow, Cardiovascular Medicine
- Noninvasive study - trans-esophageal echocardiograms (indication: valve, infection, ...)
- Usual sedative has cardiac suppression effects; want to study during the T-E echo
- Trans-thoracic echo done before and then after TE
- Look at systolic and diastolic function
- LVEF is one of the main response variables; 3-D echo probe to better quantify, or use 2-D
- Would like to assess if changes due to the sedative has clinical implications
- Other studies have used only visual LVEF
- Main analyses could be based on the Wilcoxon signed-rank test (pre vs. post); report confidence intervals for the mean differences
- Sample size calculations will need standard deviations for the within-patient difference for a few of the main response variables
- A conservative estimate could be based on an ordinary standard deviation
- Could also be done as a sequentially monitored study that could be terminated when confidence intervals for mean differences have desired precision. See https://data.vanderbilt.edu/biosproj/CI2/handouts.pdf
Abraham Mukolo - Peabody Human and Organizational Development
- Two datasets; one with individual-level data; clustered data from sample survey; have population weights
- Need to make sure that population-level estimates are needed, otherwise use of sample weights will downweight some of the observed data, losing efficiency (increasing standard errors)
- Can this be done in SPSS?
- Bring laptop if want to look further into SPSS options
- Oluwole_Biostat_Clinic.xls: data file for Olalekan Oluwole
Ideas, requests, problems regarding Vanderbilt Biostatistics Wiki? Send feedback